
AWS DevOps Agent Revolutionizes Incident Management with AI-Powered Reasoning and Multi-Agent Architecture

In a significant stride towards autonomous operations, Amazon Web Services (AWS) has unveiled the AWS DevOps Agent, an innovative solution poised to transform how organizations manage and resolve complex incidents in distributed systems. Designed to combat common pitfalls like confirmation bias and telemetry overload, the agent leverages a sophisticated multi-agent architecture and a deep understanding of application topology to streamline incident response, from initial alert to proactive prevention. This development marks a critical evolution in site reliability engineering (SRE) and DevOps practices, offering a new paradigm for maintaining system health and business continuity in an increasingly intricate technological landscape.
The Challenge of Modern Incident Response: Navigating Complexity and Cognitive Bias
Modern distributed systems, characterized by microservices, serverless functions, and dynamic cloud infrastructure, have introduced unprecedented levels of complexity. While these architectures offer agility and scalability, they also present formidable challenges for incident management. The sheer volume of telemetry data—metrics, logs, traces—generated by these systems can overwhelm human operators, making it difficult to discern signal from noise.
One of the most insidious obstacles in incident investigations is confirmation bias. Under the immense pressure of a production outage, an on-call engineer might form an initial theory based on limited triage information or past experience. Once a single piece of supporting evidence is found, the investigation often prematurely halts, leading to an incomplete or incorrect root cause identification. This can result in prolonged downtime, repeated incidents, and significant financial repercussions. Industry reports frequently highlight that the average cost of an IT outage can range from tens of thousands to millions of dollars per hour, underscoring the critical need for faster, more accurate incident resolution. Moreover, a substantial portion of outages are attributed to human error or misdiagnosis, emphasizing the limitations of even the most skilled engineering teams when confronted with high-stress, data-rich environments.
Traditional incident management tools often excel at collecting data but fall short in providing the reasoning capabilities needed to synthesize disparate information, generate multiple hypotheses, and rigorously test each one against comprehensive evidence. This gap between abundant telemetry and actionable intelligence is precisely what the AWS DevOps Agent aims to bridge, introducing an autonomous, reasoning-driven approach to incident resolution.

A New Paradigm: The AWS DevOps Agent’s Multi-Agent Architecture
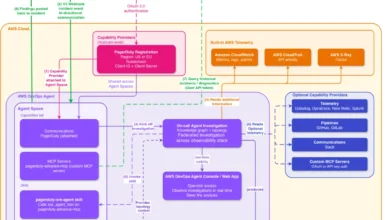
At its core, the AWS DevOps Agent is an autonomous system built on a multi-agent architecture, where specialized agents collaborate to address different facets of incident operations. This design mirrors the highly effective operational models of elite SRE teams, breaking down complex tasks into manageable, optimized capabilities. Unlike systems that merely aggregate data or provide AI-assisted insights, the DevOps Agent actively reasons about system behavior, challenging assumptions and converging on true causes only when evidence is conclusive.
The agent’s ability to operate effectively hinges on a fundamental architectural understanding of the environment it monitors. Without this context, any AI agent would be searching blindly through vast oceans of telemetry. The AWS DevOps Agent distinguishes itself by building a dynamic, living map of resources, their interdependencies, runtime communication patterns, and deployment lineage—a critical foundation for intelligent investigation and proactive prevention.
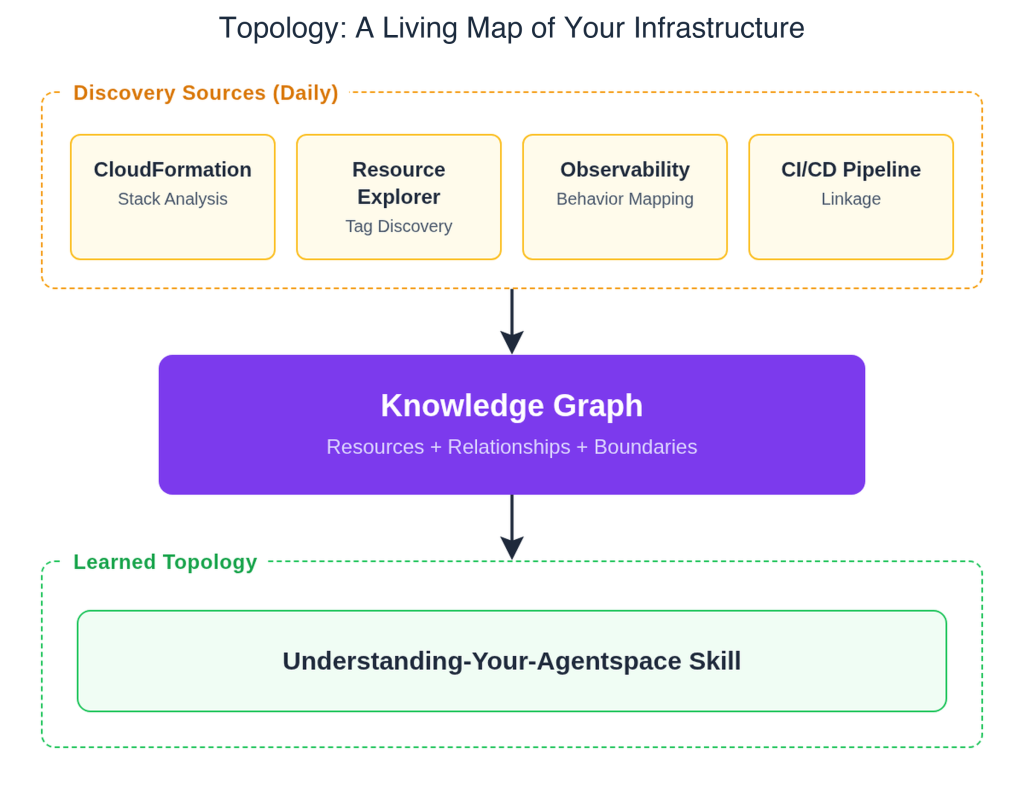
The Foundation: Architectural Awareness through the Topology Graph
Before any incident investigation can commence, the AWS DevOps Agent establishes a comprehensive understanding of the system’s architecture. This is not a static inventory but a continuously updated, dynamic "application topology graph." This graph maps not only which resources exist but also how they logically and functionally relate to one another, how they communicate during runtime, and their connection back to the code and deployment processes that provision and modify them.
The topology engine constructs this intricate understanding through several complementary discovery approaches:
- AWS CloudFormation Stack Analysis: Including AWS CDK, which synthesizes to CloudFormation, allowing the agent to understand infrastructure as code definitions.
- Tag-Based Discovery: Utilizing AWS Resource Explorer, the agent identifies and categorizes resources based on metadata.
- Behavioral Mapping: Through sources like CloudWatch Application Signals and integration with third-party platforms such as Dynatrace and Datadog, the agent observes and learns runtime communication patterns between services.
- CI/CD Pipeline Integration: By connecting with tools like GitHub Actions and GitLab CI/CD, the agent links resources to their deployment processes and specific code changes, providing crucial lineage context.
The result is a "learned topology," meticulously built and continually refined by the agent’s "understanding-your-agentspace" skill. This graph captures static infrastructure relationships, dynamic runtime communication patterns, and critical deployment lineage. During an investigation, this foundation allows the agent to trace failures through dependencies; during mitigation, it helps assess the blast radius of proposed fixes; and throughout, it correlates issues with recent changes. This architectural context transforms the agent from a data aggregator into a reasoning entity, enabling it to follow dependencies, understand impact, and link issues to their origins.
Each "Agent Space"—a logical container scoped to a specific team, service, or application—maintains its own isolated topology graph, investigation history, and integrations, ensuring operational clarity and security.
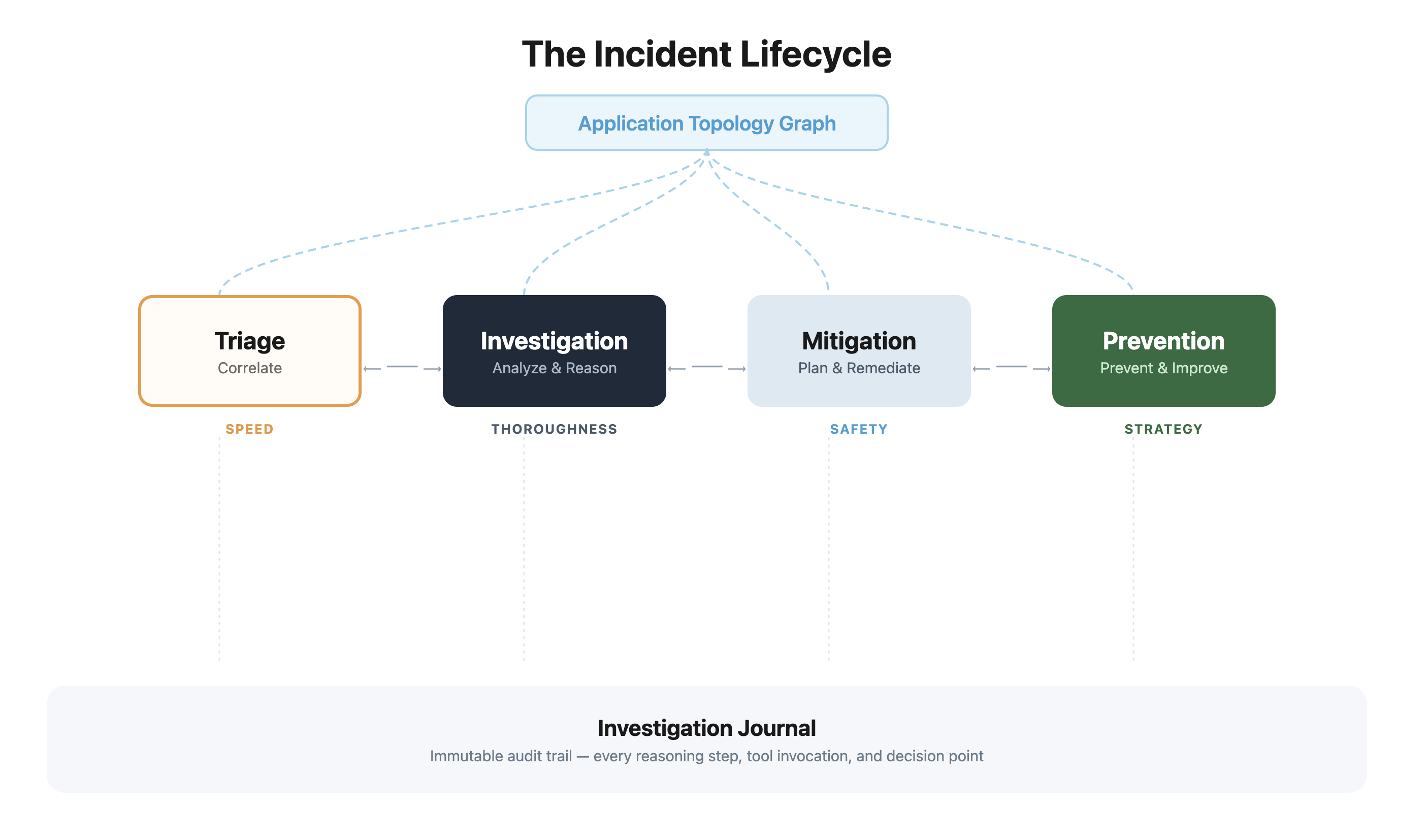
The Incident Lifecycle: A Step-by-Step Breakdown
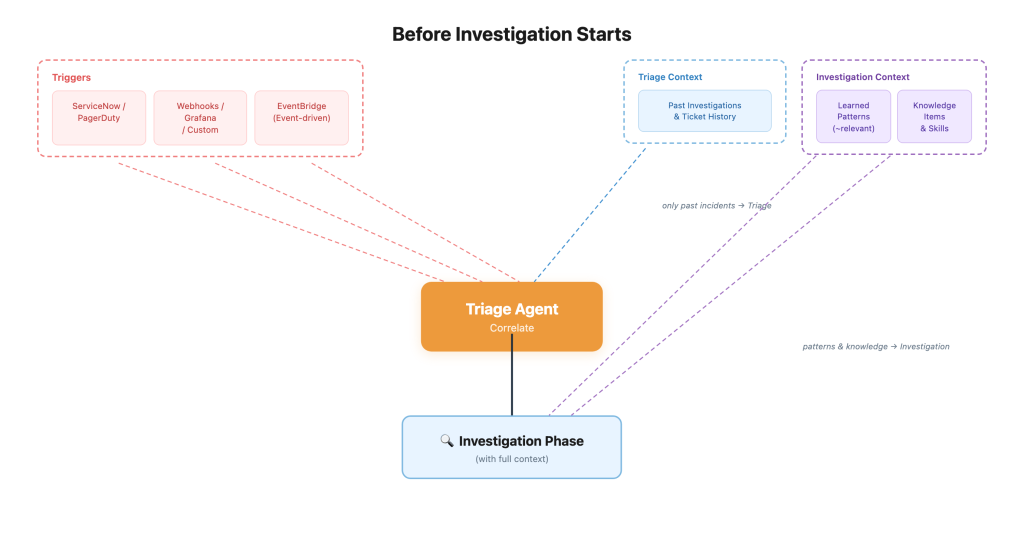
The AWS DevOps Agent organizes incident response into a structured lifecycle, mirroring the best practices of high-performing SRE teams. This lifecycle comprises Triage, Investigation, Mitigation, and Learning, all underpinned by the application topology graph and an immutable Investigation Journal.
-
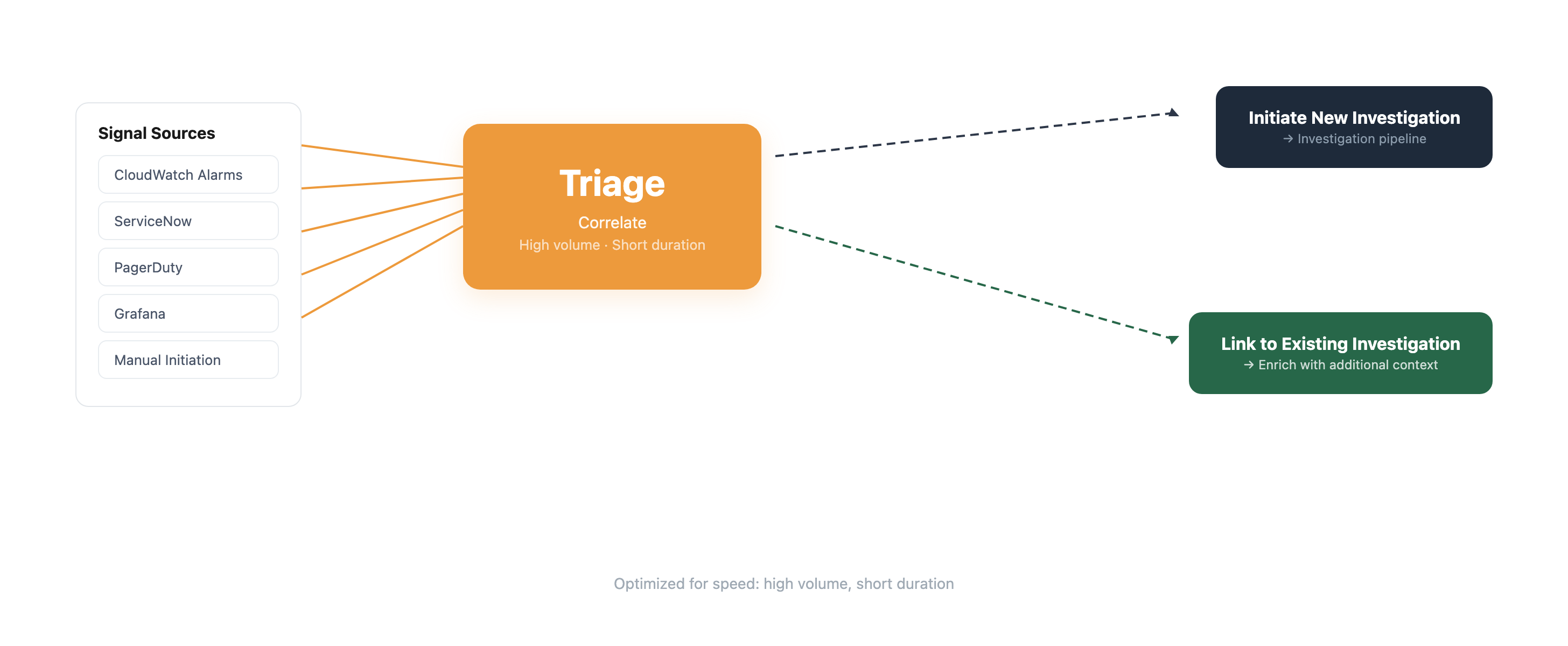
Rapid Triage and Correlation: The First Line of Defense
When an incident is triggered—whether from CloudWatch Alarms, third-party monitoring tools like ServiceNow, PagerDuty, or Grafana, or initiated manually—the Triage capability immediately activates. Optimized for speed and high-volume processing, Triage’s primary goal is fast classification and correlation.A key function of Triage is automatically correlating incoming signals. In a complex distributed system, a single underlying problem can manifest as multiple alerts across different services and monitoring platforms. Without correlation, each alert could initiate a separate, fragmented investigation, wasting valuable time and resources. Triage identifies when alarms originate from the same underlying event, funneling related evidence into a single, comprehensive investigation. This significantly reduces noise and allows teams to focus their attention on the most critical, consolidated issues. While the agent makes initial correlation decisions at machine speed, human operators retain full control, able to unlink alerts and spawn separate investigations if their judgment dictates. Once signals are correlated and enriched with initial context, the investigation seamlessly transitions to the deeper analysis phase.
-
Deep Investigation: The Reasoning Engine in Action
Investigation is the core of the AWS DevOps Agent, where its multi-hypothesis reasoning engine truly shines. It adopts a structured methodology that mirrors how seasoned DevOps engineers approach problems, but at a speed and scale impossible for humans.-
Context Acquisition and Data Collection: Every investigation begins by answering two fundamental questions: "What’s affected?" and "What changed recently?" The agent parses the incoming signal to understand the scope—identifying symptomatic resources, defining the relevant time window, and incorporating any initial information provided by the operator. It then traverses the topology graph outwards from the affected resources, mapping the blast radius to include direct dependencies, upstream producers, and downstream consumers. Recent deployment activities are pulled from connected CI/CD pipelines, and the current incident pattern is cross-referenced with past investigations.
With this situational map, the agent casts a wide net for evidence. It collects time-series metrics, comparing them against healthy baselines to detect subtle deviations. Log streams are queried across integrated observability platforms (CloudWatch, Splunk, Datadog), filtered to relevant resources and error signatures. Distributed traces are captured to visualize request flows through affected paths. Crucially, it also gathers configuration states and constructs a chronological timeline of deployments, configuration changes, scaling events, and alarm triggers. This comprehensive data aggregation ensures no stone is left unturned.
-
Hypothesis Generation: With all relevant evidence collected, the agent simultaneously generates multiple competing root-cause theories. These hypotheses aren’t random guesses but are derived from different analytical lenses applied to the gathered data. Some hypotheses emerge from pattern matching, recognizing symptoms that resemble known failure signatures from previous incidents. Others are born from anomaly detection, flagging metrics that have sharply deviated from their established baselines. The agent also checks for temporal correlation with recent deployments, evaluates whether upstream or downstream services are exhibiting their own problems, and scrutinizes resource constraints—such as connection pool exhaustion, CPU headroom limits, or quota ceilings—that could explain degradation under load.
The agent then rigorously validates each hypothesis using both supporting and counter-evidence before presenting them to operators. For instance, in a scenario where an e-commerce checkout service experiences latency spikes, the agent might simultaneously generate hypotheses regarding a recent configuration change, slow responses from a payment gateway, and database connection pool saturation. It would then systematically examine each: confirming the config change only affected logging (eliminating it), noting the payment gateway slowness began after the checkout latency (identifying it as a symptom, not the cause), and finally correlating the 94% connection pool capacity with the exact onset time, with no contradictory evidence. This meticulous process ensures the actual root cause is identified, preventing engineers from chasing red herrings.
-
Root Cause Determination: The agent synthesizes evidence across validated hypotheses, distinguishing correlation from causation and identifying primary versus contributing causes. Ambiguity is flagged when evidence is inconclusive. The final output of the investigation is a clear, validated root cause, accompanied by a structured mitigation plan.
-
-
Safe Mitigation Strategies: Human-in-the-Loop for Execution
With the root cause established, the AWS DevOps Agent generates a detailed mitigation plan. This plan adheres to a deliberate structure: a remediation strategy, step-by-step procedures, validation checks to verify system state before applying changes, success criteria to assess whether the fix worked, and crucially, explicit rollback procedures to reverse the changes if something goes wrong.A cornerstone of the AWS DevOps Agent’s design is its commitment to safety. While it generates comprehensive mitigation plans, it does not autonomously execute remediation actions. The agent’s write capabilities are strictly limited to actions like ticket or support case creation. The plans themselves may recommend specific commands, configuration changes, or code modifications, but the ultimate execution remains with the human operator. This deliberate separation ensures that a human reviews the proposed plan, understands its potential impact (assessed by the agent’s topology awareness), validates the rollback procedures, and makes a conscious decision to proceed. This "human-in-the-loop" model is vital, as applying fixes under pressure is often the most critical and potentially dangerous moment during an incident.
-
Proactive Prevention and Continuous Learning: From Reactive to Resilient
The true long-term value of the AWS DevOps Agent extends beyond incident resolution to proactive prevention. The Prevention capability analyzes patterns across past incidents, even when their surface symptoms appeared vastly different. For example, a latency spike in an API, a timeout in a batch processor, and an error rate in a notification service might all trace back to the same underlying database scaling issue. Without sophisticated pattern analysis, these would be treated as three unrelated incidents. The agent identifies these common root causes, enabling organizations to address systemic weaknesses rather than merely patching individual symptoms.These identified patterns lead to targeted recommendations across several domains:
- Observability Enhancements: Suggesting monitoring gaps, alert tuning, and tracing coverage improvements.
- Testing and Validation: Recommending deployment validation procedures and chaos engineering practices.
- Code Resilience Patterns: Advising on retry logic, circuit breakers, and improved error handling.
- Infrastructure Optimization: Guiding capacity planning, autoscaling configurations, and right-sizing.
- Governance Guardrails: Proposing pipeline bake time suggestions, test validation gates, and pipeline integration tests.
Recommendations are dynamic and responsive to operator feedback. Engineers can accept them into their backlog or reject them with natural language explanations, which in turn refines future suggestions. These recommendations persist until explicitly acted upon, ensuring teams maintain control over their operational backlog. This continuous learning loop—where investigations feed prevention, and prevention improves the environment—creates an operational flywheel. Over time, this leads to fewer incidents, significant reductions in engineering hours spent on reactive firefighting, and a more resilient system overall. The more the agent investigates, the more it prevents; the more it prevents, the fewer incidents a team faces.
Broader Implications for DevOps and SRE
The introduction of the AWS DevOps Agent carries significant implications for the broader fields of DevOps and SRE. It represents a shift from purely reactive incident response to a more intelligent, proactive, and continuously learning operational model.
- Reduced Mean Time To Resolution (MTTR): By automating context acquisition, multi-hypothesis generation, and evidence validation, the agent drastically cuts down the time required to identify root causes, directly impacting MTTR and minimizing downtime.
- Mitigation of Human Error and Cognitive Load: By offloading the initial, high-pressure investigation phases, the agent reduces the cognitive burden on on-call engineers, allowing them to focus on strategic decisions and complex problem-solving rather than sifting through endless data. This also significantly reduces the impact of confirmation bias.
- Enhanced System Resilience: The Prevention capability enables organizations to move beyond addressing individual incidents to tackling systemic vulnerabilities, leading to more robust and stable systems over time.
- Operational Consistency and Knowledge Transfer: The agent’s immutable investigation journal, topology graph, and persistent prevention recommendations ensure that operational context and lessons learned are captured and retained within the system, independent of individual team members. This is invaluable for onboarding new engineers and maintaining institutional knowledge across team changes.
- Cost Efficiency: By reducing downtime and freeing up engineering hours previously spent on manual incident investigation, the AWS DevOps Agent offers substantial cost savings and allows highly skilled engineers to focus on innovation.
Industry analysts suggest that such advancements are critical for enterprises grappling with the scale and complexity of modern cloud environments. Experts in site reliability engineering highlight the pressing need for tools that can mitigate human error and cognitive biases during high-pressure incidents. The AWS DevOps Agent addresses these needs directly, offering a glimpse into the future of autonomous operations.
Conclusion
The AWS DevOps Agent connects its diverse capabilities into a powerful operational flywheel. The topology graph provides architectural awareness to every stage—guiding investigations to trace failures and informing mitigation strategies about potential blast radii. Investigation findings flow directly into Prevention, enabling the identification of systemic patterns that individual incidents cannot reveal. These prevention recommendations, in turn, lead to environmental improvements, influencing the nature of subsequent incidents and making each cycle of resolution and prevention more efficient.
For engineers on-call, often working late into the night, juggling dashboards, and battling notification floods, the AWS DevOps Agent offers a transformative ally. It ensures that competing theories are rigorously tested against counter-evidence, that reasoning is transparently documented, and that mitigation plans include robust rollback procedures. Operational context, which once resided solely in the minds of experienced engineers, now lives within the system itself, readily available to anyone stepping into the on-call rotation.
AWS encourages organizations to explore the capabilities of the DevOps Agent, inviting feedback on current incident investigation approaches and aspirations for AI-driven assistance. Users can create their first Agent Space within AWS DevOps Agent in the AWS Management Console and embark on their initial investigation, experiencing firsthand the power of intelligent, autonomous incident management.






{kind=link}