
The Evolution of AI Agents: From Conversationalists to Executors
Historically, large language models (LLMs) were confined to generating text based solely on their training data. While adept at conversation and creative writing, they lacked the ability to interact with the real world or access live, external information. If prompted for current weather conditions or real-time stock prices, these models could only apologize for their inability to fetch live data or, worse, fabricate an answer. This inherent limitation stemmed from their design as closed-loop systems, detached from external APIs and databases. The advent of "tool calling," also known as "function calling," represents a foundational architectural shift designed to bridge this critical gap, transforming static conversational models into dynamic, autonomous agents capable of executing real-world tasks.
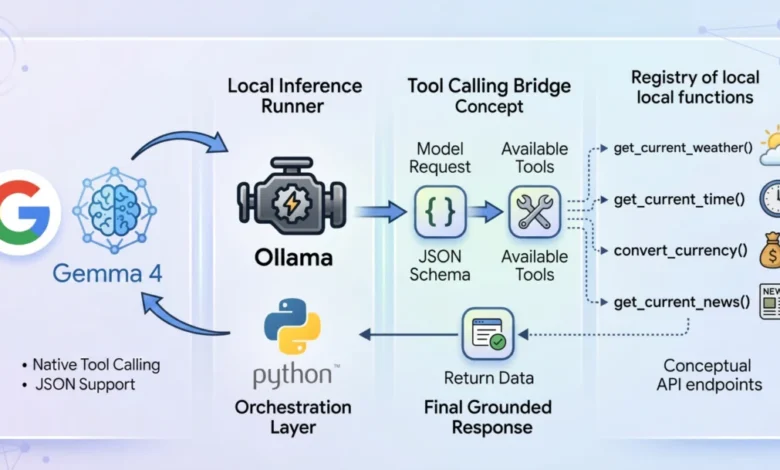
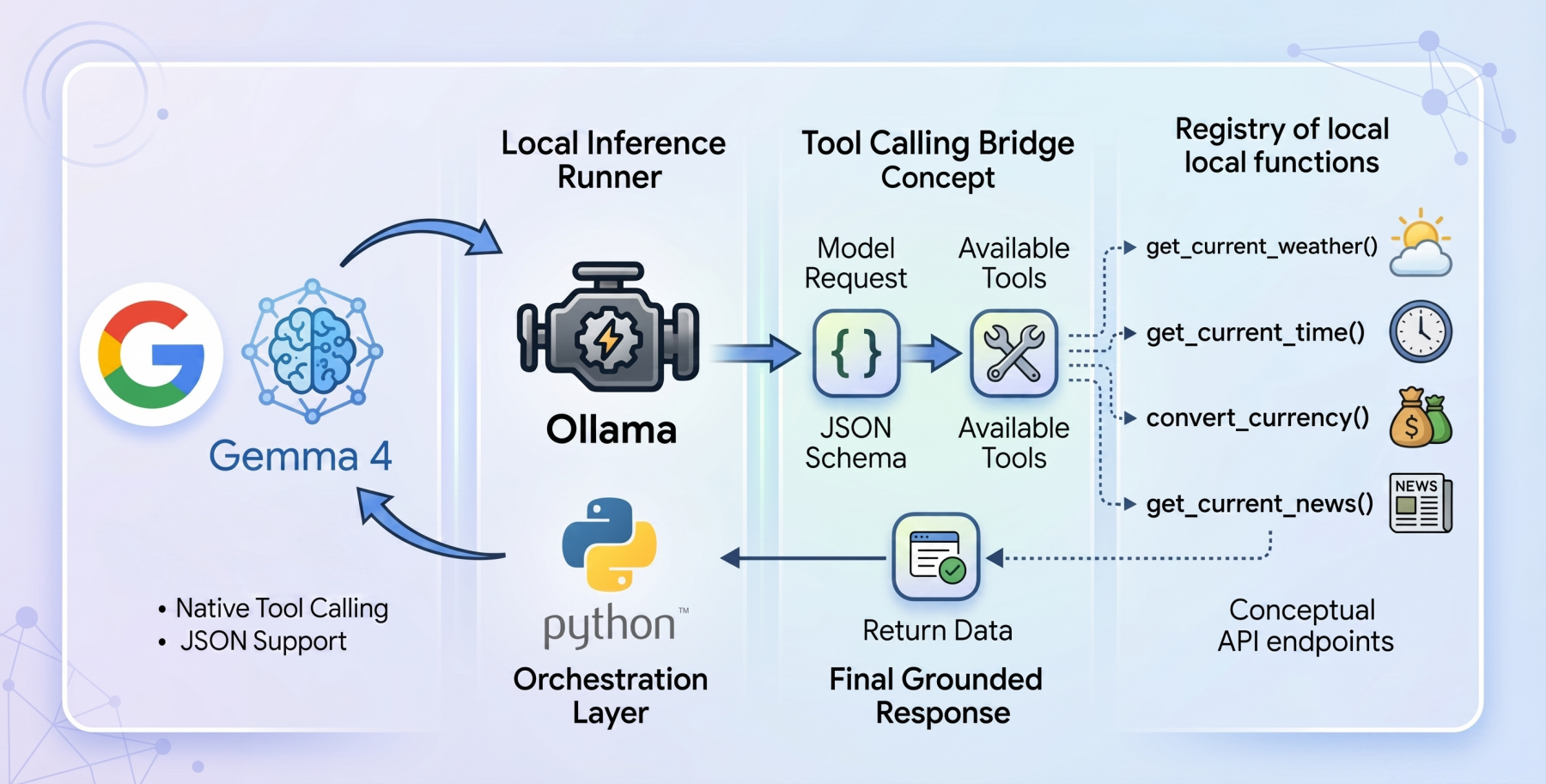
Tool calling functions as an intelligent interface, enabling an LLM to evaluate a user’s prompt against a predefined registry of available programmatic tools. These tools are typically described to the model via a structured JSON schema. Instead of attempting to infer an answer from its internal weights, the model intelligently pauses its inference process. It then formulates a precisely structured request, designed to invoke a specific external function, and awaits the outcome. Once the host application processes this request and returns the result, the model synthesizes this newly injected, live context to formulate a grounded, accurate, and relevant final response. This mechanism effectively expands the LLM’s operational horizon, allowing it to retrieve current information, perform calculations, or interact with digital services, thereby moving beyond mere text generation to active problem-solving.
Gemma 4: Google’s Contribution to the Open-Weight Ecosystem
The release of the Gemma 4 model family by Google has significantly reshaped the open-weights model ecosystem. Positioned as a direct competitor to other leading open-source models, Gemma 4 was engineered to deliver frontier-level AI capabilities under a permissive Apache 2.0 license. This licensing choice is critical, empowering machine learning practitioners with complete control over their infrastructure and, crucially, their data privacy. Unlike proprietary models, Gemma 4 allows for local deployment and fine-tuning without vendor lock-in or concerns about data egress, making it particularly attractive for sensitive applications.
The Gemma 4 family is diverse, featuring models tailored for various computational needs. It includes parameter-dense variants like the 31B model and the structurally complex 26B Mixture of Experts (MoE), designed for high-performance tasks. Complementing these are lightweight, edge-focused variants optimized for deployment on devices with limited resources. A standout feature for AI engineers is the native support for agentic workflows. These models have been meticulously fine-tuned to reliably generate structured JSON outputs and natively invoke function calls based on system instructions. This integrated capability transforms Gemma 4 models from probabilistic reasoning engines into practical systems capable of orchestrating complex workflows and interacting seamlessly with external APIs, all while operating locally.
Ollama and the Edge: The Pillars of Privacy-First Deployment
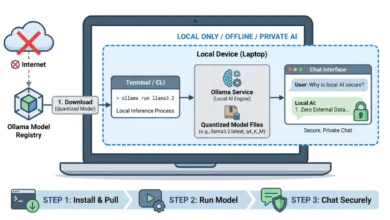
To construct a truly local, privacy-first tool-calling system, the combination of Ollama as the local inference runner and the gemma4:e2b (Edge 2 billion parameter) model proves to be particularly potent. Ollama has emerged as a popular, user-friendly platform for running large language models locally, abstracting away much of the complexity of model deployment and management. Its ease of use has significantly contributed to the democratization of LLM experimentation and application development on personal hardware.
The gemma4:e2b model is a testament to advanced AI engineering, specifically designed for mobile devices and IoT applications. Despite its incredibly compact size, activating an effective 2 billion parameter footprint during inference, it represents a paradigm shift in what is achievable on consumer-grade hardware. This optimization is crucial for preserving system memory and achieving near-zero latency execution, which is vital for responsive user experiences. By executing entirely offline, gemma4:e2b eliminates concerns about rate limits and API costs, while rigorously preserving data privacy, as no data leaves the local environment. Remarkably, Google has engineered gemma4:e2b to inherit the multimodal properties and native function-calling capabilities of its larger 31B counterpart. This makes it an ideal foundation for building fast, responsive desktop agents and allows developers to thoroughly test the capabilities of the new model family without requiring a high-end Graphics Processing Unit (GPU), broadening accessibility.
Architecting the Agent: A Zero-Dependency Philosophy for Portability
The implementation of this local tool-calling agent adheres to a stringent zero-dependency philosophy, leveraging only standard Python libraries such as urllib for network requests and json for data serialization. This design choice maximizes portability and transparency, significantly reducing the potential for software bloat, dependency conflicts, and security vulnerabilities often associated with external libraries. The complete code for this tutorial, demonstrating this lean architectural approach, is openly available on a dedicated GitHub repository.
The architectural flow of the application operates in a methodical, multi-stage process. Upon receiving a user query, the system initiates an interaction with the gemma4:e2b model running locally via Ollama. This initial request includes the user’s prompt and a registry of available tools, described in a standardized JSON schema. The model then processes this input, determining whether the query necessitates the invocation of one or more tools. If a tool call is identified, the system dynamically executes the corresponding Python function, feeding the live data generated by the tool back into the conversational context. Finally, the model performs a secondary inference pass, synthesizing this external data with its internal knowledge to formulate a coherent and contextually accurate final response to the user.
Building Functional Bridges: The Tooling Mechanism in Detail
The effectiveness of an AI agent heavily relies on the quality and clarity of its underlying functions. Consider the get_current_weather function, a quintessential example of an external tool. This Python function is designed to interact with the open-source Open-Meteo API to retrieve real-time weather data for a specified location. The function employs a two-stage API resolution pattern: initially, it transparently intercepts the city string provided by the model and geocodes it into precise latitude and longitude coordinates. This step is crucial because most weather APIs require strict geographical coordinates rather than city names. With the coordinates in hand, the function then invokes the weather forecast endpoint and constructs a concise natural language string representing the telemetry data, such as temperature and wind speed.
However, merely writing the Python function is only half the process. For the gemma4:e2b model to understand and correctly invoke this tool, it must be visually informed about its structure and parameters. This is achieved by meticulously mapping the Python function into an Ollama-compliant JSON schema dictionary. This rigid structural blueprint is paramount. It explicitly details the expected variables (e.g., city, unit), their data types (e.g., string), strict string enumerations (e.g., "celsius", "fahrenheit"), and required parameters. This precise schema guides the gemma4:e2b model’s weights, enabling it to reliably generate syntax-perfect function calls with the correct arguments, significantly reducing the likelihood of errors or misinterpretations.
Tool Calling Under the Hood: The Autonomous Workflow
The core of the autonomous workflow unfolds within the main loop orchestrator. When a user submits a query, an initial JSON payload is established for the Ollama API. This payload explicitly links the gemma4:e2b model and appends a global array containing the parsed toolkit definitions (the JSON schemas). This initial interaction allows the model to analyze the user’s intent in the context of the available tools.
Upon resolution of this initial web request, a critical evaluation of the returned message block occurs. The system does not blindly assume text-based output. Instead, the model, being aware of the active tools, signals its desired outcome by attaching a tool_calls dictionary within the response if it determines that an external function is needed. If this tool_calls dictionary exists, the standard synthesis workflow is paused. The system then parses the requested function name and its arguments (kwargs) from the dictionary block. It proceeds to dynamically execute the corresponding Python tool with these parsed arguments. The live data returned from the tool’s execution is then injected back into the conversational array, appended as a message with a "tool" role.
This process highlights a crucial secondary interaction: once the dynamic result from the tool is appended, the entire messages history, now including the tool’s output, is bundled up a second time and sent back to the Ollama API. This second pass is what empowers the gemma4:e2b reasoning engine to process and interpret the real-world telemetry strings it previously initiated. It bridges the final gap, allowing the model to synthesize the external data with its internal knowledge and output a logically grounded, human-readable response. This iterative communication loop ensures that the agent’s responses are not only contextually relevant but also factually accurate, based on live information.
Expanding Capabilities: A Modular Approach to Agent Development
With the architectural foundation firmly established, enriching the agent’s capabilities becomes a straightforward process of adding modular Python functions. Employing the identical methodology described for get_current_weather, developers can incorporate additional live tools. For instance, the system was expanded to include functions for convert_currency (fetching live exchange rates), get_current_time (retrieving local time for a specified city), and get_latest_news (accessing recent news headlines). Each new capability is rigorously processed through the JSON schema registry, effectively expanding the baseline model’s utility without necessitating complex external orchestration or the burden of heavy third-party dependencies. This modularity not only simplifies development but also enhances the maintainability and scalability of the agent, allowing for rapid iteration and expansion of its functional repertoire.
Real-World Validation: Testing the Agent’s Prowess
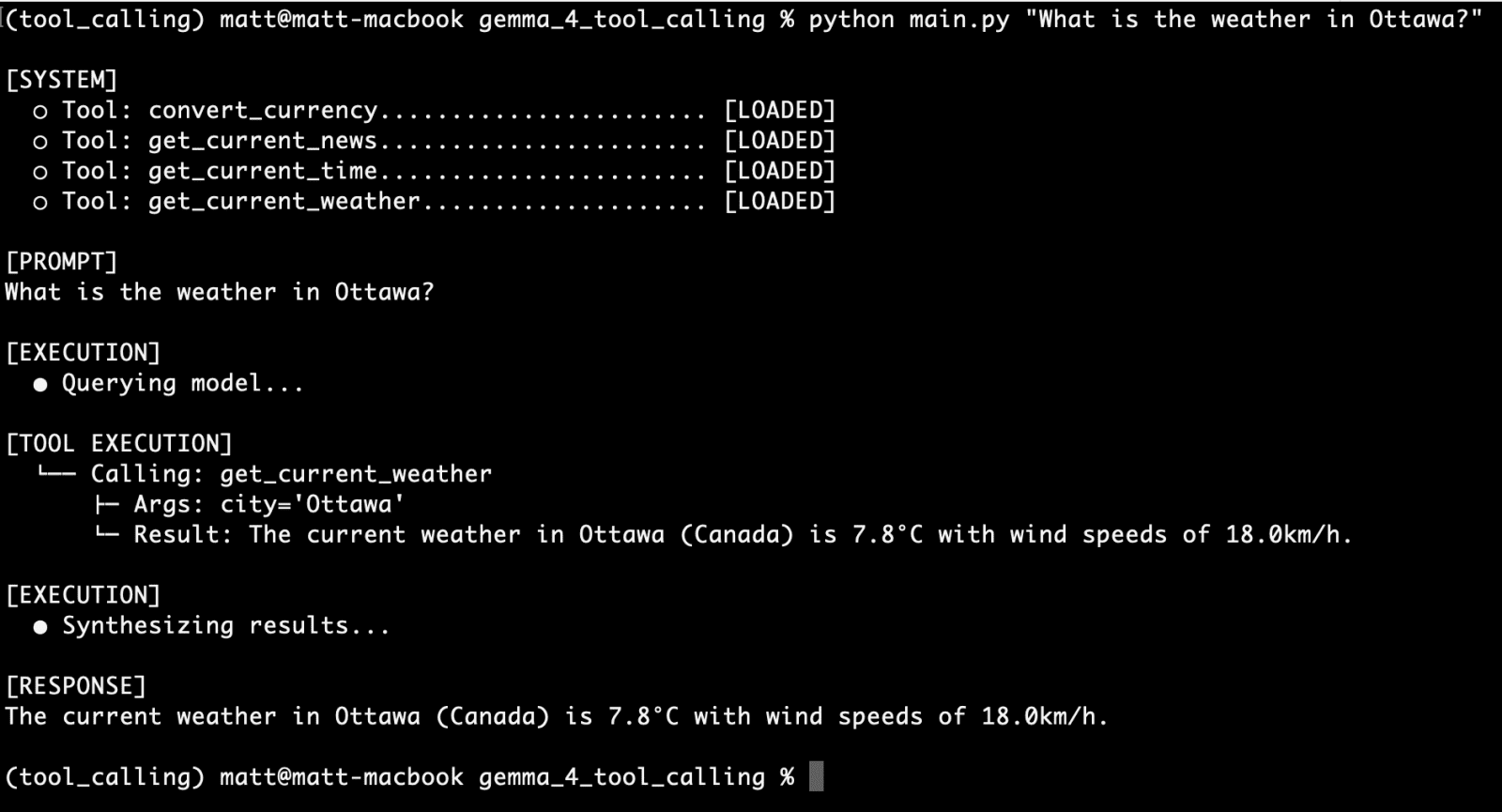
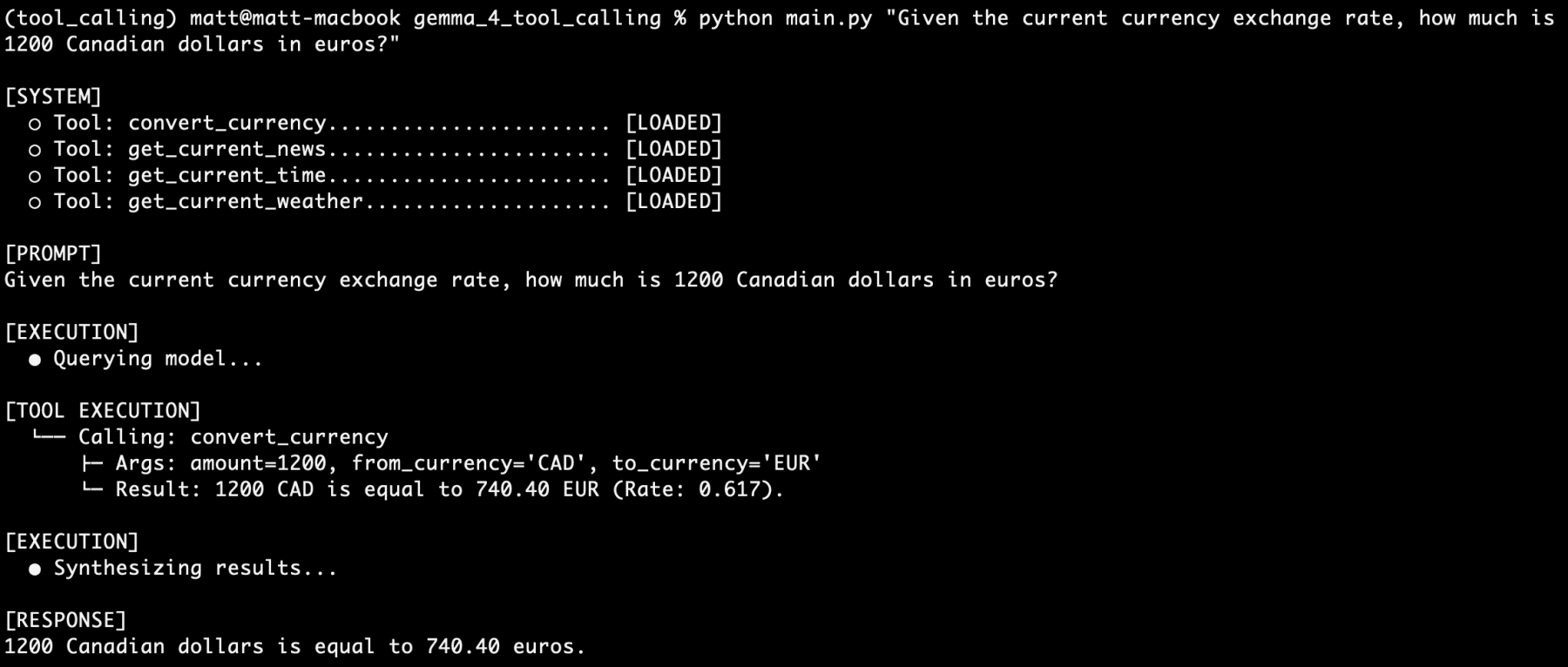
The true test of any AI system lies in its real-world performance. The tool-calling agent, powered by Gemma 4 and Ollama, underwent a series of validation tests to assess its reliability and accuracy. Initial tests focused on individual tool functionalities. For example, a query such as "What is the weather in Ottawa?" successfully triggered the get_current_weather function. The command-line interface (CLI) output clearly demonstrated the model’s recognition of the tool, its invocation, and the subsequent display of real-time weather data, confirming a successful first run. Similarly, the convert_currency tool was independently validated with a query like "Given the current currency exchange rate, how much is 1200 Canadian dollars in euros?" The agent accurately performed the conversion, again showcasing its ability to access and process live financial data.
The ultimate challenge involved stacking multiple tool-calling requests within a single, complex user prompt. A multi-faceted query like, "I am going to France next week. What is the current time in Paris? How many euros would 1500 Canadian dollars be? What is the current weather there? What is the latest news about Paris?" served as a rigorous test. Despite the complexity and the need to invoke four different functions—get_current_time, convert_currency, get_current_weather, and get_latest_news—the gemma4:e2b model, remarkably, processed each request accurately and synthesized a comprehensive response. This robust performance, achieved on a local setup with a model half of whose parameters are active during inference, underscores the efficiency and sophisticated reasoning capabilities of Gemma 4. Throughout extensive testing, involving hundreds of prompts with varying degrees of vagueness, the model’s reasoning consistently proved reliable, demonstrating a significant leap in the practical application of local AI agents.
Broader Implications and the Future of Local AI
The advent of native tool-calling behavior within open-weight models like Gemma 4, facilitated by local inference runners such as Ollama, represents one of the most practical and impactful developments in the field of local AI in recent times. This paradigm shift enables developers to operate securely offline, constructing complex, sophisticated systems unfettered by the common restrictions of cloud services and proprietary APIs. By architecturally integrating direct access to external resources—be it the web, local file systems, raw data processing logic, or localized APIs—even low-powered consumer devices can now achieve levels of autonomy that were previously exclusive to cloud-tier hardware and significantly more resource-intensive models.
This development holds profound implications across various sectors. For enterprises, it paves the way for highly secure, on-premises AI solutions that can interact with internal systems and sensitive data without privacy concerns. For individual users, it promises a new generation of personal AI assistants that offer intelligent, context-aware assistance directly from their devices, enhancing privacy and reducing reliance on internet connectivity. Furthermore, for the rapidly expanding fields of edge computing and the Internet of Things (IoT), these capabilities unlock unprecedented potential for intelligent, distributed systems. The demonstrated reliability of Gemma 4 in handling complex, multi-tool queries signals a clear path towards building fully agentic systems capable of proactive problem-solving and autonomous decision-making. The combination of open-weight models, local deployment, and robust tool-calling mechanisms is not merely an incremental improvement; it is a fundamental redefinition of what is possible with accessible, privacy-preserving artificial intelligence, charting a course towards a future where sophisticated AI agents become a pervasive and integral part of our digital lives.






{kind=link}