
DigitalOcean Unveils AI-Powered Documentation Assistant, Revolutionizing Developer Support with Gradient AI Platform
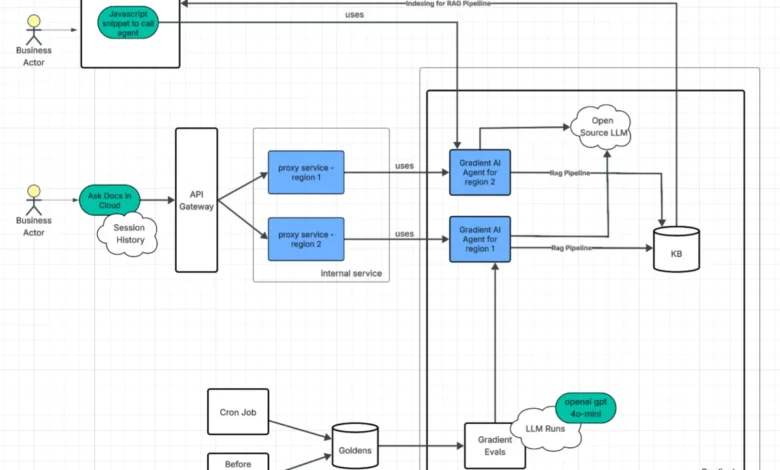
At DigitalOcean, the pursuit of developer efficiency has consistently placed documentation at the forefront of its product development strategy. Recognizing that a developer’s ability to quickly resolve issues is paramount, the company has unveiled a sophisticated AI-powered documentation assistant. This new tool aims to dramatically reduce the time developers spend navigating complex support materials, transforming a process that could previously take minutes into one that now takes mere seconds. The underlying technology, built upon DigitalOcean’s Gradient AI Platform, represents a significant leap forward in how technical documentation can be accessed and utilized, moving beyond static pages to an interactive, intelligent assistant.
The impetus for developing this AI assistant stemmed from a critical observation: traditional documentation, while functional, imposes a cognitive burden on users. Developers are required to possess prior knowledge of where to locate specific information, meticulously scan through lengthy articles, and then translate generic instructions into the context of their unique technical environments. This often time-consuming process is precisely what DigitalOcean sought to streamline. The result is an AI agent capable of understanding natural language queries and providing precise, actionable answers, complete with working links and ready-to-use commands. While the initial concept was straightforward, bringing this AI assistant to a production-ready state involved extensive iteration and refinement, particularly in ensuring the AI’s responses were consistently grounded in factual documentation.
The core challenge lay not in the AI’s ability to generate plausible responses, which was achievable from the outset, but in rigorously verifying that these responses were factually accurate and remained so across model updates and prompt modifications. This focus on accuracy and reliability consumed the majority of the development effort. This article delves into the architectural design, validation methodologies, and strategic decisions that propelled the AI assistant’s performance from "not great" to "ready for launch." It will explore the intricacies of prompt engineering, the implementation of robust evaluation pipelines, and the essential CI/CD infrastructure that underpins its operation. Crucially, the development process heavily leveraged DigitalOcean’s Agentic Inference Cloud, enabling the team to concentrate on product behavior rather than the complex integration of inference, retrieval-augmented generation (RAG), and evaluation tooling.
Architectural Foundation: Gradient AI Platform as the Control Plane
DigitalOcean’s Gradient AI Platform serves as the central control plane and runtime environment for deploying production-ready AI agents without the need for manual assembly of disparate components. This integrated platform allows users to attach knowledge bases, define agent configurations, and fine-tune their behavior within a single, cohesive interface. Developers can select their preferred Large Language Model (LLM), whether managed or open-source, and adjust parameters such as temperature and top-P for response creativity and randomness. Furthermore, the platform offers granular control over retrieval behavior and the system prompt, facilitating rapid prototyping from an empty project to a functional agent within minutes, thereby eliminating the need to manually wire together inference, RAG, and evaluation systems from scratch.
A Gradient AI Agent, in this context, is the tangible outcome of these configurations—a specifically tailored AI agent designed for a particular task, such as providing answers to documentation queries. This deployed product is built upon the foundational building blocks of the Gradient AI Inference Cloud. It is not a separate entity but rather a named, production-ready instance that can be operated and rigorously evaluated. For the documentation assistant, the choice of an "Agent" over a raw completion API was driven by product fit. The requirement for task-oriented question-answering, with a strong emphasis on grounding and conversational follow-up capabilities, perfectly aligned with the agentic paradigm.
The AI agent is accessible through two distinct interfaces, each designed to address specific operational needs and user scenarios.
Direct Script Embedding: Rapid User Integration
The most straightforward approach involves embedding a Gradient AI JavaScript snippet directly into the DigitalOcean documentation website. This method was implemented early in the development cycle, providing a low-cost and efficient way to expose the AI agent to a broad user base swiftly. This embedded script generates an authentication token, enabling seamless interaction with the Gradient AI Agent. This initial deployment allowed for rapid user feedback and early validation of the core functionality.
API Gateway and Proxy: Enhanced Control and Observability
A more sophisticated integration utilizes an API Gateway and an internal proxy service. This architecture positions the proxy between the user and the Gradient AI Agent. Authentication in this model leverages the user’s existing DigitalOcean session, offering a more integrated and secure experience compared to generated tokens. The added complexity of the proxy proved to be a worthwhile investment, primarily because it facilitates the measurement of Time to First Token (TTFT). By handling streaming responses from the Gradient AI Agent, the proxy layer can capture accurate latency figures without requiring direct instrumentation of the agent itself.
Beyond latency monitoring, operating the proxy as an internal service provided several critical capabilities that would have otherwise necessitated custom development:
- Enhanced Security: The proxy acts as a security layer, managing authentication and authorization before requests reach the AI agent.
- Request/Response Transformation: It can preprocess incoming requests and format outgoing responses, ensuring compatibility and consistency.
- Observability and Logging: The proxy provides a centralized point for logging requests, responses, and agent interactions, crucial for debugging and performance analysis.
- Rate Limiting and Throttling: It can implement traffic management policies to protect the AI agent from overload.
- Load Balancing: Distributing requests across multiple agent instances ensures high availability and scalability.
The deployment strategy involves multiple proxy instances across various regions, each paired with its own Gradient AI Agent. These agents are provisioned using Terraform, a robust infrastructure-as-code tool that eliminates the configuration drift often associated with manual setup through a user interface. This ensures consistency and reproducibility. In the event of a proxy instance failure, a load balancer automatically redirects traffic to another available instance, establishing a highly resilient architecture with no single point of failure.
Inference Infrastructure: Powering Agentic Workloads
A pivotal consideration in building AI-driven automation is the selection of an appropriate inference layer. For straightforward, high-speed, ephemeral completion calls, Serverless Inference offers direct access to foundation models with automatic scaling and a pay-per-token pricing model. This is ideal for workloads characterized by a simple "call model, get text" pattern.
AI agents, however, address a different class of workload. These are multi-step, conversational, and retrieval-grounded flows. While they utilize ephemeral completion calls under the hood, the agent platform orchestrates these calls. This orchestration involves injecting RAG context, fine-tuning parameters like temperature, rewriting queries, and chaining steps together. The emphasis here shifts from raw model output to sophisticated agentic behavior and product-specific functionality.
.png)
Agents represent the most direct path to ensuring answers are intrinsically linked to a specific domain. They augment Serverless Inference with knowledge base grounding and intelligent orchestration, delivering retrieval capabilities, session-aware conversational flows, and managed RAG integration within a unified product offering, thereby minimizing the number of moving parts.
In practice, this translates to default configurations that DigitalOcean did not need to build or operate independently. For instance, retrieved document chunks are re-ranked for relevance before the model generates an answer, enhancing grounding without requiring a custom ranker. The Gradient Agent intelligently maintains session context across conversational turns, enabling follow-up questions to be handled naturally, rather than as independent, fresh completions. During the indexing of documentation, the platform automatically managed the cleaning and chunking of content, significantly reducing manual ingestion efforts and ensuring consistent retrieval behavior across a vast corpus of documents.
While the Gradient AI Agent operates on managed inference, abstracting the underlying serving stack, teams requiring absolute control over their serving infrastructure—such as custom images, hardware pinning, or bespoke scaling solutions—can opt for GPU Droplets, Bare Metal GPUs, or DigitalOcean Kubernetes (DOKS) with their own custom inference layers. This alternative is suitable when a "managed agent endpoint" does not align with specific operational demands. For DigitalOcean’s documentation assistant, the synergy of a managed agent, integrated knowledge base, and built-in evaluation capabilities provided the optimal balance for rapid iteration and operational simplicity.
Data-Driven Validation: The Cornerstone of Reliability
While traditional development best practices like reliability and scalability are crucial, they are insufficient in AI development if the agent itself is prone to hallucination or fails to achieve its intended purpose. A robust validation framework is therefore indispensable.
Key Performance Metrics
It quickly became apparent that making changes to prompts or agent settings without rigorously measuring their impact was an inefficient use of resources. A comprehensive suite of metrics was developed to provide objective insights into the agent’s performance. These metrics fall into two categories: LLM-judged metrics, which require more time and computational resources, and deterministic metrics, which are fast, inexpensive, and predictable.
DigitalOcean settled on a balanced approach incorporating both types of metrics:
- Correctness (LLM as Judge): This metric leverages an LLM to evaluate the factual accuracy of the agent’s responses, effectively identifying and mitigating open-domain hallucinations—fabricated information not supported by any source document.
- Ground Truth Adherence (LLM as Judge): This measures the semantic equivalence between the agent’s response and a pre-defined, accurate reference answer. While Correctness asks "Is this true?", Ground Truth Adherence probes "Is this the correct answer to this specific question?" A response can be factually accurate yet fail to address the user’s underlying intent.
- Time to First Token (TTFT) (Deterministic): This measures the latency from the moment a request is made to when the agent begins to generate a response. TTFT is a critical user-perceived performance indicator, as noticeable delays can significantly detract from the user experience.
- URL Correctness (Deterministic): This metric employs regular expressions to extract all DigitalOcean documentation links from the agent’s response and subsequently verifies that each extracted URL returns a successful HTTP response. The agent’s core function is to guide users to relevant documentation, and broken links undermine this purpose immediately.
To deem the Product Documentation agent ready for release, DigitalOcean established specific performance thresholds: an 80% ground truth adherence and 95% correctness. These benchmarks were determined by carefully weighing the risks associated with accuracy, the potential impact on users, and the reliable capabilities of the evaluation pipeline. Reaching these targets necessitated multiple iterative refinements, with specific adjustments directly influencing each metric.
Enhancing Correctness and Ground Truth Adherence
The improvement of correctness and ground truth adherence was primarily achieved through layered prompt engineering:
- Instruction Tuning: The system prompt was meticulously tuned to guide the LLM’s behavior. This involved providing clear instructions on how to interpret queries, prioritize information sources, and format responses. For example, specific instructions were added to ensure the agent defaulted to using information from the control panel for certain types of queries.
- Few-Shot Examples: Incorporating a curated set of example question-answer pairs within the prompt helped the LLM understand the desired response style and accuracy. These examples served as concrete demonstrations of correct behavior.
- Retrieval Method Optimization: The retrieval method was shifted from "rewrite" to "sub-queries" to improve the relevance of retrieved document chunks, particularly for complex and multifaceted questions. This change allowed the system to break down intricate queries into smaller, more manageable parts, leading to more precise information retrieval.
The "golden datasets"—collections of question-and-answer pairs considered to be the definitive correct answers—underwent numerous passes to rectify inaccuracies. This included correcting factually erroneous ground truth entries (such as issues related to monitoring webhooks and GPU model errors), clarifying ambiguous questions by incorporating specific product context, and establishing a dedicated validation set to ensure the agent could effectively ask clarifying questions when faced with vague terminology.
Further fine-tuning involved setting the LLM’s temperature to 0.1 for reduced randomness and configuring retrieval with k=10 (retrieving the top 10 relevant chunks). Strict response constraints were also implemented: avoiding exhaustive lists, answering in direct terms mirroring the documentation’s plain language, using pricing and plan details only from retrieved documents or directing users to the official pricing page when such information was absent from the context, and defaulting to Control Panel steps unless the query explicitly requested API instructions.
The golden datasets themselves were also significantly overhauled. This process involved correcting inaccurate answers, removing community questions where lengthy, informal answers did not align with the agent’s intended concise style, reducing question ambiguity, and introducing per-product topic tags for more granular performance tracking.
Optimizing TTFT (Time to First Token)
Three key adjustments were instrumental in improving the TTFT metric:
- Model Selection: Exploring and selecting LLM models known for their faster inference speeds contributed directly to reduced latency.
- Infrastructure Optimization: Enhancements to the underlying inference infrastructure, including optimizing server allocation and network configurations, played a crucial role in speeding up response times.
- Prompt Optimization for Speed: Certain prompt structures or excessive token generation instructions could inadvertently increase processing time. Streamlining prompts to be more direct and less computationally intensive for the LLM helped in achieving quicker first-token delivery.
Fortifying URL Correctness
URL correctness was a distinct area of focus, addressed by developing a custom URL correctness metric and scorer. This tool systematically extracts URLs from agent responses and verifies their resolvability. The extraction regular expressions were iteratively refined to accommodate edge cases, such as trailing punctuation, extraneous characters, and periods that are legitimately part of a URL path.
Prompt-side adjustments included the addition of explicit rules:
- Prefer Official Documentation: The prompt was updated to explicitly instruct the agent to prioritize URLs from
docs.digitalocean.com. - Exclude Non-Documentation Links: The agent was directed to avoid generating links to community forums, third-party websites, or personal blogs.
- Validate URL Existence: Instructions were reinforced to ensure that any provided URL points to a valid and accessible resource.
Furthermore, the knowledge base itself was rigorously inspected. OpenSearch chunk inspection notebooks were utilized to confirm that the knowledge base contained exclusively docs.digitalocean.com URLs, thereby eliminating a significant source of invalid links at the retrieval layer.
Golden Datasets: The Foundation of Rigorous Evaluation
The efficacy of DigitalOcean’s evaluation process hinges on "golden datasets"—meticulously curated collections of question-and-answer pairs that represent the definitive correct responses. A typical entry in a golden dataset includes the question, the ground truth answer, and supplementary metadata. For instance, a golden dataset entry might look like this:
question: How do I rotate my DigitalOcean API tokens securely?
answer: >
Create a new API token on the API page, update your applications to
use the new token, then revoke the old token. This ensures continuous service
while maintaining security by eliminating access through the old token.
product: api
reasoning: moderate
source: synthetic
type: how_to_configurationThe metadata associated with each entry provides crucial context for evaluation and analysis:
- Product: Identifies the specific DigitalOcean product the question pertains to, enabling granular performance tracking.
- Reasoning: Indicates the complexity of the question and the expected reasoning process from the AI.
- Source: Specifies how the dataset entry was generated (e.g., synthetic, real user query).
- Type: Categorizes the question based on its nature (e.g., how-to, configuration, troubleshooting).
These golden datasets are processed through the Gradient AI Platform, where metrics are computed. The evaluation framework employs an LLM-as-a-Judge approach, utilizing multiple GPT-4o instances from OpenAI. These judges employ Chain-of-Thought (CoT) reasoning to assign a numerical score between 0 and 1. For example, a correctness score of 0.66 would signify that two out of three judges deemed the response accurate.
Once evaluation results are generated, the metrics and associated metadata are transmitted as telemetry via OTLP to DigitalOcean’s observability cluster, facilitating ongoing monitoring and in-depth analysis.
Creating High-Quality Datasets
The creation of golden datasets involves several systematic approaches:
- Synthetic Generation: Leveraging LLMs to generate realistic questions and answers based on specific documentation content. This allows for rapid scaling and coverage of a wide range of topics.
- User Query Analysis: Analyzing anonymized real-world user queries from support tickets and search logs to identify common pain points and frequently asked questions.
- Subject Matter Expert (SME) Curation: Engaging domain experts to craft high-fidelity question-answer pairs, ensuring the accuracy and relevance of the content.
Given that golden datasets are utilized by both automated systems and human reviewers across various roles—including Product Managers, Engineers, and Managers—the YAML format was chosen for its inherent readability, especially for multi-line responses and code snippets. These YAML files are subsequently converted to CSV format and fed into the Gradient evaluations.
The generated datasets are submitted as pull requests on GitHub to a dedicated team for review and approval. This workflow ensures that only high-quality, verified responses are incorporated, with subject matter experts contributing efficiently and with minimal overhead.
Executing Robust Evaluations
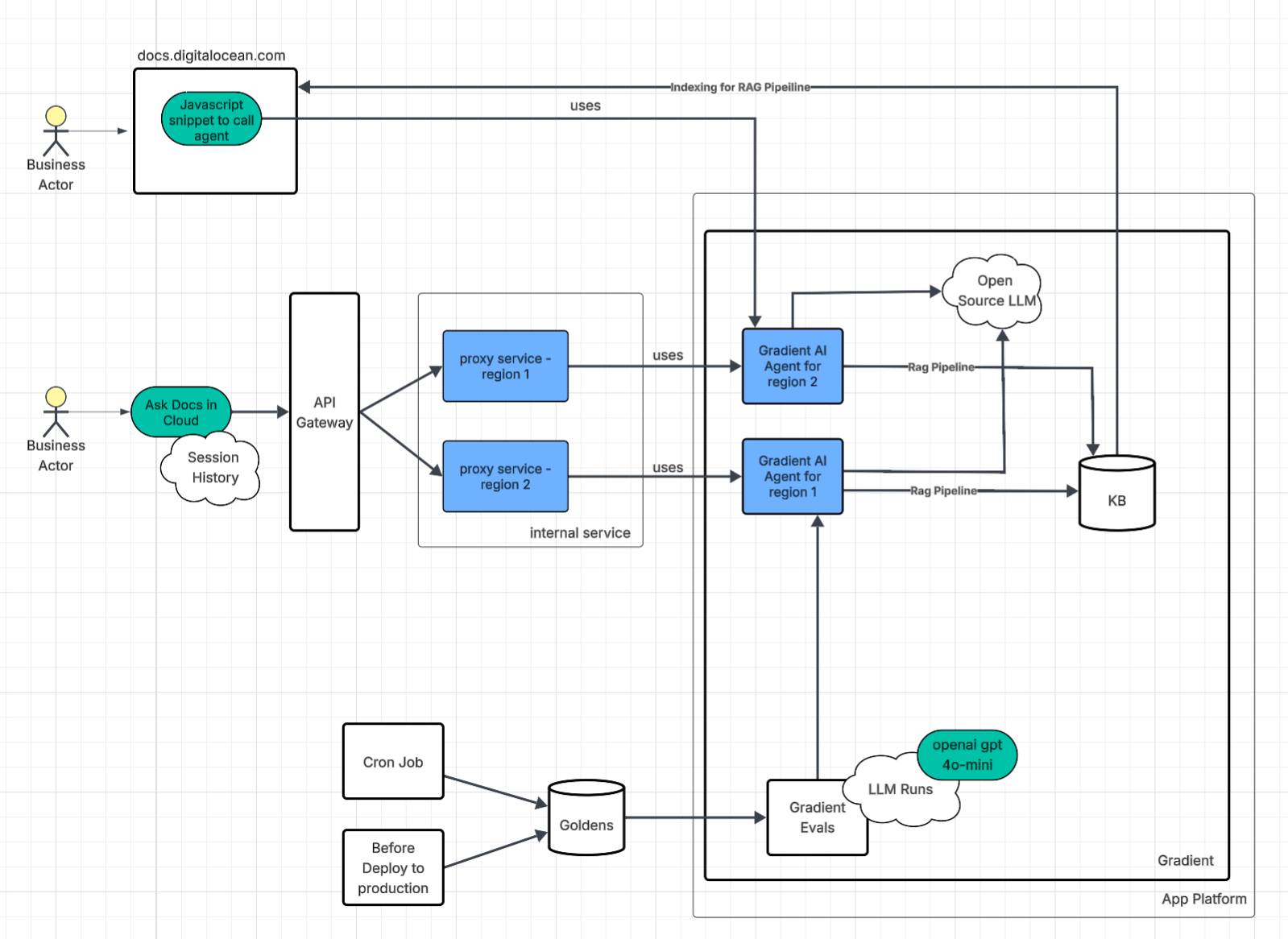
The agent evaluations are integrated into both the development process and the CI/CD pipeline via GitHub Actions. During development, engineers can experiment with changes, such as prompt updates, and run local evaluations to assess their impact. Upon merging changes, the CI/CD pipeline automatically executes comprehensive evaluations before deployment. Furthermore, the full evaluation suite is run daily to continuously verify that the documentation agent continues to perform as expected.
Agent Configuration Decisions: Iterative Refinement Through Data
With robust evaluation metrics and datasets in place, DigitalOcean could transition from subjective testing and intuition-based adjustments to objective, data-driven iteration on critical aspects like correctness and speed.
Prompt Engineering for Precision
Analysis of evaluation results revealed that the primary reason for ground truth adherence metrics falling below the 80% target and correctness metrics below 95% was the LLM’s tendency to autonomously interpret ambiguous terms or decide how to suggest actions. For instance, consider the prompt: "How do I create a Droplet on DigitalOcean?"
Based on Gradient evaluation results, the agent’s responses to such a question varied across evaluation runs. Sometimes it would provide instructions for creating Droplets via the Control Panel, while other times it would suggest using the Public API or doctl. Since the agent is integrated within the Control Panel, specific instructions were added to the prompt to ensure that ambiguous requests would primarily elicit Control Panel instructions:
- **If public API or automation is NOT specified in the question:**
- Use ONLY Control Panel chunks in your primary answer
- If only public API chunks are retrieved, ask clarifying question: "Would you like to know how to do this in the
Control Panel or via the API?"
- You may mention API/CLI methods in the Recommendation section as alternative automation optionsThe team also identified that their golden datasets contained ambiguous prompts, such as: "How do I automate deleting files older than 30 days?" Questions of this nature could yield varied responses because files can reside on numerous DigitalOcean products. This led to two key refinements:
- Clarifying Ambiguous Terms: The prompt was enhanced to include instructions for the agent to ask clarifying questions when encountering ambiguity. For example, if a user asks about "deleting files," the agent might ask: "Are you referring to files within an App Platform deployment, on a Block Storage volume, or perhaps within Spaces?"
- Structured Ambiguity Handling: A specific rule was added:
**If uncertainty exists**, ask clarifying question: "Are you asking about [Product A] or [Product B]?"
Finally, it was observed that certain keywords within prompts led to inconsistent results. The following prompt adjustment helped the agent better associate specific words with particular products. In cases where words remained too ambiguous, a dedicated clarification prompt was implemented to improve agent performance:
Identify keywords that map to specific products:
- "app" / "deployment" / "build" → App Platform
- "volume" → Block Storage
- "registry" / "container" / "DOCR" → Container Registry
- "droplet" / "VM" / "server" → Droplets
- "workflow" / "gradient" / "notebook" / "gen ai" → Gradient AI Platform
- "1-click" → Marketplace
- "function" / "serverless" → Serverless Functions
- "spaces" / "bucket" → Spaces
- These words alone are ambiguous – ask clarification:
- "image"
- "plan"
- "quota"
- "storage"
- "subscription"
- "tag"Experimentation with Data-Driven Comparisons
The non-deterministic nature of LLM responses necessitated reliance on the established metrics framework for comparing different configurations, rather than subjective assessment of outputs. This allowed for objective measurement of performance improvements.
Multiple configurations were tested, including:
- Baseline: A single shared knowledge base and a single agent.
- Product-Specific Agents: One agent per product, each with its own dedicated knowledge base.
- Hybrid Approach: A shared knowledge base combined with product-specific knowledge bases, accessed by a single agent.
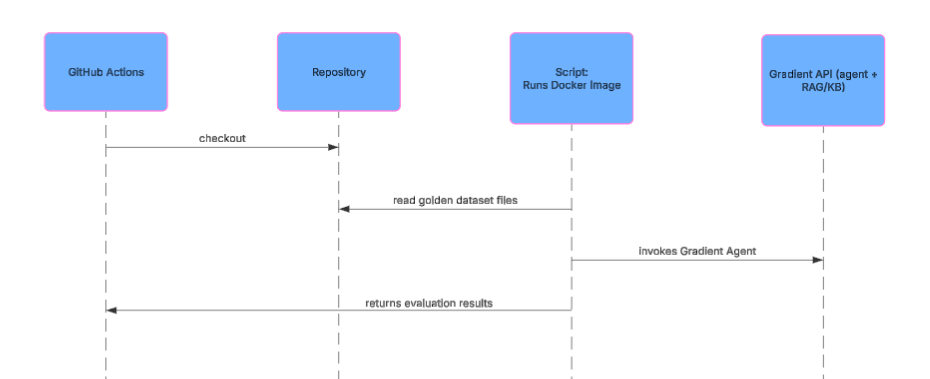
The experimental results indicated that dedicating one agent per product, each with its own knowledge base, yielded a slight correctness improvement of approximately 4%. While this gain is statistically significant, the associated operational overhead of maintaining multiple agents was deemed substantial. Consequently, DigitalOcean opted to continue with a single agent and a single common knowledge base for operational simplicity and scalability.

Due to the non-deterministic nature of the results, the same set of tests were run multiple times to obtain a reliable average. Each point represents the overall correctness for a full test run. Yellow: baseline (one shared KB, one agent). Green: one agent, four product KBs. Blue: shared KB plus four product KBs.

Yellow: baseline (one KB, one agent). Green: four small KBs, each with its own agent, no shared KB. Blue: four agents on small KBs plus a shared KB on the main agent.
These experimental decisions would not have been feasible without the comprehensive evaluation metrics in place. Every change, from prompt modifications to architectural experiments, was measured, adjusted, and re-measured to ensure meaningful improvements in the agent’s performance.
Top 3 Must-Dos for Production AI Agent Development
The efforts that ultimately made DigitalOcean’s AI agent reliable enough for production release were not necessarily the most anticipated. They involved provisioning agents via Terraform rather than manual UI clicks, constructing comprehensive golden datasets before a single prompt was ready for testing, and integrating evaluations into the CI/CD pipeline to ensure no change was deployed without demonstrable improvement.
1. Treat Your Agent Like a Production System
If an AI agent is user-facing, it must adhere to the same rigorous standards as any other service in your technology stack. This includes robust monitoring, built-in redundancy, and the implementation of infrastructure-as-code. DigitalOcean utilizes Terraform for agent provisioning and deploys agents across multiple regions to ensure high availability. The AI agent is treated as a critical service, not a peripheral project.
2. Define "Good" and Measure It Rigorously
Clearly defining what constitutes a "good" performance for your agent is paramount. This involves selecting metrics that align precisely with your product requirements, building comprehensive golden datasets, and conducting regular evaluations. Relying on assumptions or intuition can be misleading; DigitalOcean’s initial evaluation runs uncovered correctness issues on questions they initially considered straightforward. Spot-checking a handful of prompts is an inadequate substitute for a fully automated evaluation suite.
3. Ship Only Changes That Improve the Numbers
Continuously run evaluations against a production-like environment. Only implement changes to prompts, retrieval mechanisms, or models when empirical data, derived from your metrics, indicates a clear improvement. Automate this feedback loop to ensure that quality is not dependent on manual processes or ad-hoc checks.
Building and Scaling AI Applications on DigitalOcean
The AI agent described herein was developed on DigitalOcean’s Agentic Inference Cloud. This platform uniquely combines inference-optimized compute with a full-stack cloud infrastructure designed to support production AI workloads, encompassing managed databases, object storage, Kubernetes, and networking services. The Gradient AI Platform served as the central hub for the agent’s development, featuring integrated knowledge bases, evaluation tools, and the iterative development loop essential for a successful launch.
Prominent companies such as Character.ai and Workato are leveraging the same infrastructure to scale their inference operations. These organizations will be sharing their experiences and insights at the Deploy conference on April 28 in San Francisco.
It is important to note that while this agent is engineered to expertly navigate DigitalOcean’s documentation, it is not infallible and can still make mistakes. The code and advice provided should be used as a guide, and users are always encouraged to apply their best architectural judgment.






{kind=link}