
Local-First Web Applications: A Comprehensive Look at Current Architectures and Future Trends for 2026
The landscape of web application development is undergoing a significant transformation, driven by an increasing demand for instantaneous user experiences, robust offline capabilities, and enhanced data privacy. While traditional client-server architectures have long dominated, the emergence and maturation of local-first patterns are reshaping how developers approach data management, synchronization, and user interaction. By 2026, local-first web applications are moving from experimental research to production-ready solutions, offering compelling advantages for a specific, yet broad, range of use cases.
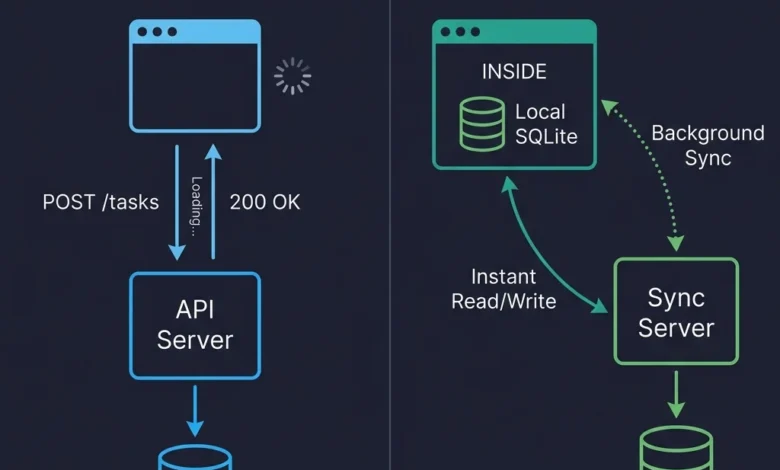
The shift towards local-first architecture is not merely an academic exercise; it’s a pragmatic response to real-world performance bottlenecks and user expectations. A developer’s recent experience in Lisbon highlights this paradigm shift vividly. Attempting to demonstrate a project management tool built with a conventional React frontend, Node backend, Postgres database, Redis cache, and GraphQL API, the application struggled with unreliable hotel Wi-Fi. The inability to load data without a server round-trip, despite a sophisticated infrastructure, exposed the inherent limitations of server-reliant models. This incident underscores a critical pain point: the dependence on remote servers, often thousands of miles away, can severely degrade user experience in the face of network instability or high latency. Such scenarios are no longer edge cases but common realities for a globally connected, mobile-first user base.
Defining Local-First: Beyond Offline and PWAs
A common misconception in the developer community conflates local-first with offline-first or Progressive Web Applications (PWAs). It is crucial to distinguish these concepts. Offline-first design ensures an application functions gracefully without network connectivity, but the central server typically remains the authoritative source of truth. Service workers, often employed for caching, improve performance by serving stale data faster, yet they do not alter data ownership. PWAs, while offering installability, caching, and push notifications, are primarily a delivery mechanism rather than a fundamental data architecture.
Local-first, in contrast, is a foundational data architecture. Its core principle dictates that the user’s device holds the primary copy of their data. The application reads from and writes to a local database, enabling instantaneous rendering and interaction. Synchronization with servers or other devices occurs in the background, making the server a peer in a distributed system, rather than a gatekeeper. While the server retains special authority for authentication, backup, and access control, it does not dictate the immediate availability or mutability of user data. This architectural philosophy was formally articulated in the seminal 2019 "Ink & Switch Local-First Software" paper, which outlined seven ideals: fast, multi-device, offline, collaboration, longevity, privacy, and user ownership. These ideals, initially viewed by some as aspirational, are increasingly becoming engineering imperatives as tooling matures. The fundamental shift lies in redefining the client from a "thin view requesting permission to show data" to a "node in a distributed system with its own database." This distinction profoundly impacts every layer of the application stack.
Strategic Adoption: When Local-First Excels and When It Doesn’t
Despite its advantages, local-first architecture is not a universal panacea. Prudent adoption requires careful consideration of an application’s specific data characteristics and operational requirements. It is generally a poor fit for applications where data is predominantly server-generated, such as analytics dashboards, social media feeds, or search results. In these scenarios, the server is the natural producer of data, and client consumption via traditional API requests remains perfectly adequate.
Furthermore, systems demanding strong transactional consistency, like banking platforms, payment processing, or real-time inventory management, are ill-suited for local-first. These domains require ACID (Atomicity, Consistency, Isolation, Durability) guarantees, where eventual consistency can lead to severe financial or operational repercussions. If two users simultaneously attempt to purchase the last item in stock, a single, authoritative database must arbitrate that decision instantly. Over-engineering simple CRUD (Create, Read, Update, Delete) applications with no inherent offline or collaboration needs also warrants caution. For an internal administrative panel used by a handful of users within a well-connected office, the added complexity of a sync engine might be unnecessary. Similarly, applications handling massive datasets that cannot practically fit on client devices pose a physical limitation.
However, local-first shines in specific contexts:
- User-generated content: Note-taking apps, document editors, collaborative design tools, and project management systems where users are actively creating and modifying data.
- Unreliable connectivity: Field applications, mobile-first tools, or any scenario where internet access is intermittent.
- Data privacy: Applications where user ownership and control over data, potentially including end-to-end encryption, are key selling points.
- Real-time collaboration: Tools requiring seamless, low-latency co-editing experiences.
A practical approach often involves a "spectrum of local-first," where specific features within an otherwise traditional application benefit from this architecture. For instance, implementing offline drafts in a blog editor or real-time collaborative notes within a standard REST-based project management tool can leverage local-first principles without re-architecting the entire system. This incremental adoption allows teams to gain experience and validate the benefits before committing to a full-scale implementation.
The Replication Paradigm: Git for Application Data
The mental model for local-first web development can be likened to Git’s distributed version control, rather than centralized systems like SVN. In SVN, a single server holds the authoritative repository, and developers check out, modify, and commit changes back to that central server. Server downtime means stalled work. Git, conversely, provides every developer with a full clone of the repository, allowing local commits, branching, and merging. Pushing and pulling updates to a remote repository occurs when ready, but the remote is not the sole source of truth.
Similarly, local-first applications equip each client device with a replica (full or partial) of relevant data. Writes occur locally, enabling instant UI updates, as the application reads directly from its local database. Synchronization then functions as a background push/pull operation. This fundamental shift eliminates the need for complex data fetching libraries like React Query or SWR, as data is no longer "fetched" but "queried" from the local store. State management simplifies, as the local database becomes the definitive state. The traditional request-response cycle is largely replaced by direct local interaction, with the sync server operating asynchronously, never forcing the user to wait.

Client-Side Data Storage: The Rise of SQLite via WebAssembly
The foundation of local-first architecture lies in robust client-side data storage. While localStorage is synchronously blocking and limited to small strings, and IndexedDB, despite its asynchronous nature and larger capacity, suffers from a notoriously cumbersome API, the real innovation for 2026 is SQLite running in the browser via WebAssembly (WASM).
SQLite, compiled to WASM and leveraging the Origin Private File System (OPFS), provides a fully functional relational database directly within the browser environment. This allows for complex SQL queries, ACID transactions, and indexing, mirroring server-side database capabilities. OPFS is a crucial enabler, offering web applications a sandboxed file system with high-performance synchronous access within Web Workers, a requirement for efficient SQLite operation. Prior to OPFS, developers often resorted to in-memory SQLite instances manually persisted to IndexedDB, a method prone to performance issues and fragility.
Libraries like wa-sqlite facilitate this integration, abstracting the complexities of WASM and OPFS. However, developers must navigate browser-specific quirks; for instance, early Safari OPFS implementations exhibited silent failures in certain iframe contexts, necessitating fallback strategies like IndexedDB-backed persistence. The trade-offs between storage options are clear: IndexedDB offers broad compatibility for moderate data but poor developer experience; OPFS + SQLite WASM delivers relational power for serious applications at the cost of a ~400KB bundle addition and potential Safari idiosyncrasies; and emerging solutions like PGlite (Postgres in WASM) promise full Postgres compatibility but are newer with larger bundle sizes and higher memory footprints. The ongoing development in this space, including CRDT-enabled SQLite extensions like cr-sqlite, indicates a rapid evolution towards more powerful and integrated client-side data solutions.
The Synchronization Challenge: CRDTs vs. Database Replication
While local data storage is increasingly a solved problem, reliable synchronization across multiple devices and users remains the primary architectural hurdle. When replicas can independently read and write, a robust mechanism for reconciling concurrent changes is essential.
Conflict-Free Replicated Data Types (CRDTs) represent a class of data structures mathematically designed to ensure concurrent edits can always be merged without conflicts. Yjs is a leading JavaScript implementation, particularly effective for real-time collaborative text editing, where character-level merges produce semantically sensible outcomes. Other notable CRDT libraries include Automerge, a Rust-backed, document-oriented solution, and Loro, a newer Rust-based contender touting superior performance. While CRDTs excel in specific scenarios like text collaboration, their merging semantics for structured data (e.g., reordering list items) can sometimes yield surprising, though technically correct, results that require application-level post-processing.
Database replication offers an alternative, often more suitable for applications not requiring Google Docs-style real-time text editing. This approach involves replicating rows between a server database (e.g., Postgres) and a client database (SQLite) using a dedicated sync engine. PowerSync provides one-way replication from Postgres to client SQLite with a defined write-back path for mutations, demonstrating stability and ease of reasoning in production. ElectricSQL aims for a more ambitious active-active synchronization between Postgres and SQLite, using "shapes" to define data replication policies. While promising a powerful developer experience, it is still maturing. Other solutions like Triplit offer a full-stack database with integrated sync, abstracting the client/server database distinction.
Event sourcing, where a log of mutations rather than the current state is synchronized, is another architectural pattern. While intellectually appealing for audit trails and certain domains, practitioners often find that reconstructing state from an event log adds complexity unwarranted for many common application types like a task board, where direct row synchronization is simpler and more efficient. The diversity and rapid evolution of these synchronization approaches highlight the need for careful evaluation and, ideally, abstraction layers to mitigate vendor lock-in.
Navigating Conflicts: Beyond Last-Write-Wins
Conflict resolution, often perceived as a daunting challenge, is a manageable problem requiring domain-specific consideration. Conflicts arise when multiple replicas modify the same data concurrently without immediate awareness of each other’s changes.
The simplest, yet often insufficient, approach is to silently accept the remote version, leading to lost local changes. A more effective strategy for most common data types is last-write-wins (LWW) at the field level. This means if User A changes a task title and User B changes its due date, both distinct field changes are preserved. A true conflict only occurs when the same field is modified by both, in which case the later timestamp (with a client ID as a deterministic tiebreaker) prevails. This method resolves approximately 95% of conflicts without user intervention for typical application data like task titles.
However, semantic conflicts pose a subtler challenge. Here, data merges cleanly at a structural level, but the combined result is nonsensical from an application perspective. For example, two users, both offline, booking different meetings into the same 2 PM slot will not trigger a structural conflict, but it creates an unacceptable double-booking. Resolving semantic conflicts necessitates application-level validation on the server during the sync process.
A pragmatic solution involves the server merging data structurally, then running it through a constraint validation layer. Instead of silently rejecting violating writes, which can lead to complex state divergence between client and server, the server accepts the write but flags the violation. This violation is then synchronized back to the client, triggering a non-blocking user notification (e.g., "Your meeting conflicts with another. Tap to resolve."). The user can then take explicit action to resolve the inconsistency, which generates a new, normal write that syncs back. While this introduces a temporary window of inconsistency, it prevents the more problematic scenario of ghost records on the client that the server refuses to acknowledge. For high-stakes content, such as legal or medical records, explicit user intervention might be required, but for most typical application data, users prefer automated resolution.

Architecting a Production Local-First Application
A typical local-first stack in 2026 for a collaborative project management tool might comprise React for the frontend, PowerSync for robust synchronization, SQLite via wa-sqlite on the client (persisted to OPFS with IndexedDB fallback for Safari), and Supabase providing Postgres, authentication, and row-level security. This architecture allows for remarkably simple component code, as direct database queries replace complex data fetching and state management logic.
Authentication largely mirrors traditional web apps, with JWT tokens or OAuth flows authenticating the sync connection rather than individual requests. Offline access is inherently supported as data is already local and was synced when the user was authenticated. Authorization, however, is critical at the sync layer. Client-side code cannot be trusted to hide unauthorized data; thus, the server must enforce access rules (e.g., PowerSync’s "sync rules" or ElectricSQL’s "shapes") to ensure only authorized data is replicated to each client. Server-side validation also checks incoming client writes against authorization rules. End-to-end encryption (E2EE) is a natural fit for local-first, allowing data to be encrypted on the client before synchronization, with the server acting as a relay for unreadable blobs, significantly enhancing privacy.
Schema migrations in a local-first environment present unique challenges. Unlike server-side migrations that target a single, controlled database, client-side migrations must account for thousands of user devices potentially running diverse schema versions. An additive migration strategy is paramount: new columns with defaults, new tables, but avoiding renaming or dropping columns unless absolutely necessary. Server-side logic must also gracefully handle mismatches from older client versions. A robust migration runner on the client checks the schema version at app startup, applying pending migrations within transactions to ensure data integrity.
Performance Characteristics and Key Considerations
Local-first applications offer inherent performance advantages. Reads and writes are virtually instantaneous, occurring directly against the local database without network latency. Querying hundreds or thousands of records locally typically takes milliseconds, resulting in a fluid, spinner-free user experience.
The primary performance cost is initial sync. Bootstrapping a local replica on first load or a new device involves downloading potentially megabytes of data. For a complex workspace, this can take several seconds on slower connections, a period typically mitigated by partial sync (replicating only active data) and user-friendly "setting up your workspace" screens. Subsequent incremental updates are generally minimal.
Bundle size and memory footprint are significant concerns. SQLite compiled to WASM adds approximately 400KB (gzipped) to the JavaScript bundle, necessitating lazy-loading to avoid blocking initial render. On mobile browsers with aggressive memory limits, a large local database can lead to tab crashes, requiring strategies like partial sync and aggressive data pruning.
Testing and Future Outlook
Testing local-first applications introduces new complexities. While unit tests for merge logic and E2E tests simulating offline/online transitions are effective, reproducing timing-sensitive bugs related to conflict resolution remains challenging. Detailed logging of sync events and conflict resolutions sent to observability stacks is crucial for post-hoc debugging. Property-based testing for CRDT logic, generating random operation sequences to assert convergence, proves particularly valuable.
The future of local-first is dynamic. The development of PGlite (Postgres compiled to WASM) hints at a future where client/server data distinctions blur, allowing identical SQL queries across the stack. The convergence of local-first with on-device AI models for enhanced privacy ("your data never leaves your device") is also a compelling prospect.
However, challenges persist. Fragmentation of sync protocols, with each engine using its proprietary method, poses a risk of vendor lock-in and complex migrations. The complexity budget is another concern; while local-first delivers significant benefits for the right applications and experienced teams, it introduces architectural overhead (sync engines, conflict resolution, client-side migrations, partial replication, sync-layer authorization) that can be a trap for simpler applications or less prepared teams.
As one developer aptly put it, "The best architecture is the one your team can debug at 2 AM." This philosophy underpins the cautious, yet optimistic, trajectory of local-first web development. For teams ready to embrace its inherent complexities, the rewards of enhanced performance, reliability, and user ownership are substantial. For those exploring, an incremental approach—starting with a single feature—offers a pragmatic path to understanding its power and applicability.





{kind=link}