Building Efficient Long-Context Retrieval-Augmented Generation (RAG) Systems with Modern Techniques
The landscape of Retrieval-Augmented Generation (RAG) is undergoing a profound transformation, driven by the exponential growth in Large Language Model (LLM) context window capabilities. For years, the foundational principle of RAG dictated a meticulous process of document segmentation, embedding, and selective retrieval of small, relevant fragments. This approach was a direct response to the inherent limitations of early LLMs, which operated with constrained and often costly context windows, typically ranging from 4,000 to 32,000 tokens. The necessity of breaking down extensive knowledge bases into digestible chunks was paramount to ensure efficiency and prevent models from exceeding their operational limits or incurring exorbitant computational costs.
However, the advent of cutting-edge models such as Google’s Gemini Pro and Anthropic’s Claude Opus has shattered these previous barriers, introducing context windows that now extend to 1 million tokens or more. This technological leap theoretically enables users to feed an entire library of novels or extensive corporate documentation directly into a single prompt. While seemingly revolutionary, this expanded capacity introduces a new set of sophisticated challenges for developers aiming to build truly efficient and reliable RAG systems. The shift from managing scarcity to managing abundance demands a re-evaluation of established RAG paradigms, necessitating innovative strategies to mitigate issues like attention loss within vast contexts and the escalating operational costs associated with processing massive token streams.
The Evolution of RAG and the Long-Context Paradigm Shift
Retrieval-Augmented Generation emerged as a critical innovation to address several fundamental shortcomings of standalone LLMs. While LLMs excel at generating coherent and contextually relevant text, they are prone to "hallucination"—producing factually incorrect or nonsensical information—and their knowledge is static, limited to their training data cutoff. RAG bridges this gap by coupling LLMs with external knowledge bases. Before generating a response, a RAG system first retrieves relevant information from a vast corpus of documents, effectively grounding the LLM’s output in verifiable data. This hybrid approach significantly enhances factual accuracy, reduces hallucinations, and allows LLMs to access real-time or proprietary information beyond their initial training.
Historically, the core RAG workflow involved:
- Chunking: Breaking down large documents into smaller, semantically coherent segments.
- Embedding: Converting these text chunks into numerical vector representations (embeddings).
- Indexing: Storing these embeddings in a vector database for efficient search.
- Retrieval: At query time, embedding the user’s query and finding the most similar document chunks in the vector database.
- Augmentation: Passing these retrieved chunks along with the user’s query to the LLM as part of its prompt.
This established methodology was optimized for the prevailing LLM architectures. The early 2020s saw a rapid increase in LLM context windows, from a few thousand tokens to tens of thousands. Each increase was met with enthusiasm, promising more comprehensive understanding. Yet, the recent leap to context windows exceeding one million tokens, as seen in models like Gemini 1.5 Pro (up to 1 million tokens) and Claude 3 Opus (200,000 tokens, with 1 million in private preview), signifies more than just an incremental improvement; it represents a paradigm shift. This unprecedented capacity challenges the very notion of "chunking" as it was traditionally understood, pushing developers to confront new complexities related to information saliency and cost-efficiency within these expansive contexts.
Navigating the New Challenges of Long-Context RAG
While the ability to ingest massive amounts of data is a game-changer, it introduces two primary hurdles:
- The "Lost in the Middle" Problem: Research has consistently shown that LLMs struggle to effectively utilize information when it is buried deep within a very long context window. Their attention mechanisms tend to prioritize information found at the beginning or end of the prompt, leading to critical details in the middle being overlooked or misinterpreted. This phenomenon, often dubbed "Lost in the Middle," can severely degrade performance despite the seemingly infinite context.
- Escalating Latency and Cost: Processing millions of tokens for every query is computationally intensive. Even with optimized models, the inference time for such massive inputs can lead to significant latency, impacting user experience. Furthermore, LLM providers typically charge based on token usage, meaning that larger context windows, if not managed judiciously, can lead to prohibitively high operational costs for applications with frequent queries.
Addressing these challenges requires moving beyond simplistic document partitioning. The focus now shifts towards sophisticated strategies for managing attention distribution, optimizing token flow, and enabling intelligent context reuse. The following five practical techniques offer a roadmap for building efficient and robust long-context RAG systems in this evolving landscape.
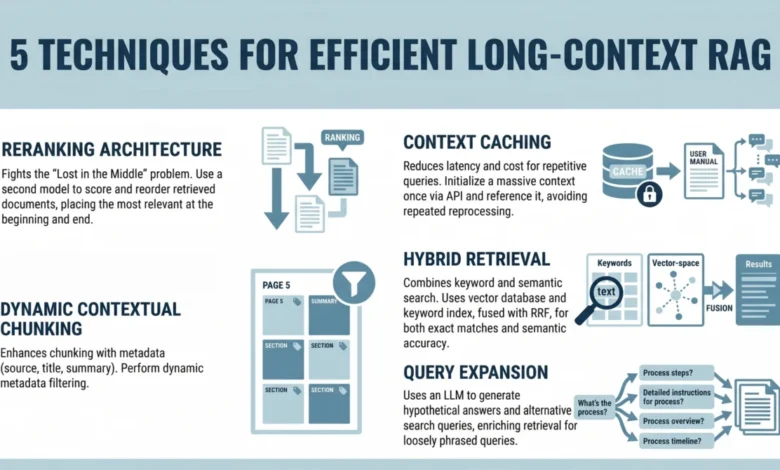
1. Implementing a Reranking Architecture to Fight "Lost in the Middle"
The "Lost in the Middle" problem, meticulously documented in a seminal 2023 study by researchers at Stanford and UC Berkeley, highlights a critical limitation in how LLMs process extended sequences of text. The study revealed that when presented with a long prompt containing relevant information, model performance significantly degrades if that information is situated in the middle of the input. Conversely, performance peaks when crucial data is placed at the very beginning or end of the context window. This attention bias necessitates a strategic approach to information presentation.
Instead of merely inserting retrieved documents into the LLM prompt in their original, often arbitrary, retrieval order, introducing a reranking step becomes imperative. Reranking is a post-retrieval optimization that re-evaluates the initial set of retrieved documents and orders them based on a more refined measure of relevance.
The developer workflow for implementing a reranking architecture typically involves:
- Initial Retrieval: The system first performs a standard retrieval operation (e.g., vector similarity search) to fetch a larger pool of potentially relevant documents (e.g., 20-50 chunks). This initial retrieval aims for high recall, casting a wide net.
- Reranking Model Application: A specialized reranker model (often a smaller, fine-tuned transformer model or a cross-encoder) then takes the user query and each of the initially retrieved documents. It scores each document based on its nuanced relevance to the query. Unlike the initial retrieval which might use dense embeddings for semantic similarity, a reranker can analyze the interaction between the query and document more deeply.
- Strategic Placement: Based on the reranker’s scores, the top N most relevant documents (e.g., 5-10 chunks) are selected. These highly relevant documents are then strategically placed at the beginning and/or end of the final prompt constructed for the main LLM, sandwiching any less critical but still potentially useful context.
This strategic placement ensures that the most important information, as determined by the reranker, receives maximum attention from the LLM, effectively mitigating the "Lost in the Middle" effect. Industry reports suggest that implementing effective reranking can improve answer accuracy by 10-20% in long-context scenarios, transforming raw retrieval into a more potent input for the generative model.
2. Leveraging Context Caching for Repetitive Queries
The sheer volume of tokens in long-context windows introduces significant latency and cost overheads. For applications where users frequently query a static or semi-static knowledge base—such as an internal company policy document, a product manual, or an FAQ system—repeatedly processing hundreds of thousands or even millions of tokens for each interaction is highly inefficient. Context caching directly addresses this challenge by storing and reusing processed context.
Think of context caching as initializing a persistent, pre-processed context for your model, rather than rebuilding it from scratch with every query. This approach involves:
- Pre-computation: For frequently accessed or static knowledge bases, the entire relevant document collection or a significant portion of it can be processed once. This includes chunking, embedding, and potentially even generating a summary or a "base context" that encapsulates the core information.
- Caching Mechanism: This pre-computed context is then stored in a cache (e.g., a dedicated memory store, a Redis instance, or a specialized LLM inference server feature).
- Dynamic Augmentation: When a user query arrives, the system first retrieves the relevant portions from the cached base context. Only the specific, query-dependent details or any new information are then dynamically added to this cached context before being sent to the LLM.
- Use Cases: This approach is particularly potent for chatbots built on static knowledge bases, customer support agents accessing product information, or internal knowledge management systems. It drastically reduces the token count for subsequent queries, leading to lower API costs and significantly faster response times. For instance, if a user asks multiple follow-up questions about a product whose manual has already been processed and cached, only the new query and a small amount of new context need to be sent to the LLM, leveraging the pre-existing understanding.
3. Using Dynamic Contextual Chunking with Metadata Filters
Even with million-token context windows, the principle of relevance remains paramount. Simply increasing the context size does not inherently eliminate noise or guarantee that the LLM will focus on the most pertinent details. Traditional static chunking, where documents are divided into fixed-size segments, often fails to capture the true semantic boundaries within a document, leading to fragmented information or the inclusion of irrelevant surrounding text.
Dynamic contextual chunking, enhanced with structured metadata filters, offers a more intelligent approach to preparing document segments for retrieval. This technique moves beyond arbitrary size limits to create chunks that are semantically coherent and precisely targeted.
- Semantic Chunking: Instead of fixed token counts, documents are chunked based on structural elements (headings, paragraphs, sections) or semantic similarity algorithms that identify natural breakpoints in the text. This ensures each chunk represents a complete idea or topic.
- Metadata Extraction: During the chunking process, rich metadata is extracted and associated with each chunk. This metadata can include:
- Document Title and Author: For source attribution.
- Section Heading: The specific heading under which the chunk appears.
- Date of Publication/Update: For temporal relevance.
- Keywords/Tags: Automatically extracted or manually assigned labels.
- Document Type: (e.g., "policy," "manual," "report," "FAQ").
- Access Permissions: For security-sensitive applications.
- Query-Time Filtering: When a user query is processed, the system first analyzes the query for explicit or implicit metadata requirements. For example, if a user asks, "What is the holiday policy for employees updated after 2023?", the system can apply filters to retrieve only chunks tagged as "policy," relevant to "employees," and with a "date_updated" greater than "2023."
- Hybrid Filtering: This metadata filtering is often combined with vector similarity search. The initial vector search retrieves a broad set of semantically similar chunks, and then metadata filters are applied to narrow down this set to only the most contextually appropriate ones.
This approach significantly reduces the amount of irrelevant context sent to the LLM, improving precision, reducing noise, and enhancing the overall quality of the generated response. It also allows for more granular control over information access and ensures that the LLM receives the most focused and accurate data for its task.
4. Combining Keyword and Semantic Search with Hybrid Retrieval
While vector search has revolutionized information retrieval by capturing the semantic meaning and contextual relationships between words, it has a notable limitation: it can sometimes miss exact keyword matches, especially for highly technical terms, specific codes, names, or precise phrases. For instance, a vector search for "GPT-4 API pricing" might prioritize documents discussing general LLM costs, potentially overlooking a document that explicitly mentions "GPT-4 API pricing" but uses slightly different surrounding vocabulary. Conversely, traditional keyword search (lexical search) excels at finding exact matches but lacks an understanding of synonymy or conceptual similarity.
Hybrid search overcomes these limitations by intelligently combining the strengths of both semantic (vector-based) and keyword-based (lexical) retrieval methods.
- Dual Retrieval Paths:
- Semantic Retrieval: The user query is embedded into a vector, and a similarity search is performed against the vector database of document chunks. This captures the conceptual relevance.
- Keyword Retrieval: The user query is also processed by a traditional search engine (e.g., Elasticsearch, BM25 algorithm) to identify chunks containing exact or closely matching keywords. This ensures lexical accuracy.
- Fusion Algorithm: The results from both retrieval paths (semantic and keyword) are then combined and re-ranked using a fusion algorithm, such as Reciprocal Rank Fusion (RRF). RRF aggregates the rankings from multiple retrieval methods, giving higher preference to documents that rank highly in both semantic and lexical searches. This ensures that documents that are both conceptually relevant and contain the exact keywords are prioritized.
- Benefits: Hybrid retrieval ensures a comprehensive approach, guaranteeing both semantic relevance (understanding the intent behind the query) and lexical accuracy (finding precise terms). This is particularly crucial for complex enterprise search scenarios, legal document analysis, medical queries, or technical support systems where specific terminology is paramount. The combined approach has been shown to consistently outperform either method in isolation, leading to a more robust and accurate retrieval phase.
5. Applying Query Expansion with Summarize-Then-Retrieve
User queries are often succinct, ambiguous, or phrased differently from how information is structured or expressed within a document corpus. This mismatch can lead to suboptimal retrieval results, even with advanced semantic search. Query expansion techniques help bridge this gap by transforming an initial user query into a richer, more comprehensive set of search terms or rephrased queries.
One powerful form of query expansion is "Summarize-Then-Retrieve" or, more broadly, using a lightweight LLM to generate alternative or hypothetical search queries.
- Initial Query: The user submits a potentially underspecified query, such as "What do I do if the fire alarm goes off?"
- LLM-Powered Expansion: A smaller, faster, and more cost-effective LLM (or even the main LLM with a specific prompt) is used to analyze the original query and generate several hypothetical alternative queries or even a hypothetical "answer" document that might contain the relevant information.
- Generated Hypotheticals:
- "Emergency procedures for fire alarms"
- "Building evacuation protocols during a fire"
- "Safety guidelines for fire incidents"
- "What steps to take during a fire drill"
- "How to respond to a fire alarm in the workplace"
- Generated Hypotheticals:
- Multi-Query Retrieval: Each of these generated hypothetical queries, along with the original user query, is then used to perform parallel retrieval operations against the vector database. This generates multiple sets of retrieved documents, increasing the chances of finding relevant information even if the original query was imperfect.
- Consolidation and Reranking: All documents retrieved from these expanded queries are then pooled together. This larger set is then typically passed through a reranker (as described in technique 1) to identify the most genuinely relevant documents to the user’s original intent.
- Hypothetical Document Embedding (HyDE): A related technique, Hypothetical Document Embedding (HyDE), uses an LLM to generate a plausible, but non-factual, hypothetical document that would answer the user’s query. This hypothetical document is then embedded, and its embedding is used to search the vector database for real documents that are semantically similar to this generated ideal answer.
This method significantly improves performance on inferential, loosely phrased, or domain-specific queries where a direct keyword or simple semantic match might fail. It proactively anticipates different ways the user’s intent might be expressed in the underlying documents, enhancing the robustness and recall of the retrieval system.
Broader Impact and Future Outlook
The emergence of million-token context windows does not eliminate the need for Retrieval-Augmented Generation; rather, it reshapes its fundamental principles and amplifies its strategic importance. The initial RAG mantra of aggressive chunking, born out of necessity, is giving way to a more nuanced understanding of information flow and attention management within vastly expanded contexts. While long contexts reduce the architectural pressure to break down documents into minuscule fragments, they simultaneously introduce a new set of sophisticated challenges related to attention distribution, latency, and the economic implications of processing immense data volumes.
The adoption of these modern RAG techniques—reranking, context caching, dynamic contextual chunking with metadata, hybrid retrieval, and query expansion—marks a significant step forward in building RAG systems that are not only scalable but also profoundly precise and cost-effective. The goal is no longer merely to provide more context to the LLM, but to ensure that the model consistently focuses on the most relevant, accurate, and timely information, irrespective of its position within a massive input.
These advancements are poised to have a transformative impact across various industries. In enterprise knowledge management, they promise more intelligent and accurate internal search capabilities, allowing employees to quickly glean insights from vast, complex document repositories. In customer service, highly personalized and context-aware chatbots can offer superior support by referencing comprehensive product manuals or user guides in real-time. For content creation and research, RAG systems can empower users to synthesize information from extensive data sets with unprecedented accuracy and efficiency.
The field of RAG remains dynamic, with ongoing research exploring even more advanced techniques, such as multi-hop retrieval (where the system performs multiple retrieval steps to answer complex questions), agentic RAG (where LLMs autonomously decide when and how to retrieve information), and self-correcting retrieval mechanisms. As LLM capabilities continue to evolve, the techniques for augmenting them with external knowledge will undoubtedly follow suit, ensuring that the promise of intelligent, factually grounded AI systems is fully realized. The current focus on optimizing long-context RAG is a crucial step in this ongoing journey, solidifying the role of sophisticated retrieval as an indispensable component of next-generation AI applications.






{kind=link}