Bridging the Context Gap: Neo4j and Microsoft Agent Framework Redefine AI Retrieval and Memory Systems
The evolution of generative artificial intelligence is currently moving away from isolated chat interfaces toward sophisticated, autonomous agents capable of handling complex, multi-step workflows. However, two persistent challenges have hindered the effectiveness of these systems: the inability of standard retrieval mechanisms to understand complex relationships within data and the lack of persistent memory across user sessions. To address these architectural gaps, Neo4j has introduced two new context providers for the Microsoft Agent Framework (MAF), integrating knowledge graph technology and persistent memory into the burgeoning AI agent ecosystem. This development marks a significant shift in how enterprise AI handles structured and unstructured data, moving beyond simple semantic similarity to a model of relational intelligence and compounding expertise.
The Limitations of Standard Retrieval and the Memory Void
To understand the significance of the Neo4j and Microsoft collaboration, one must first examine the limitations of standard Retrieval-Augmented Generation (RAG). Traditional RAG systems operate by breaking documents into "chunks" and retrieving them based on semantic similarity using vector search. While effective for simple queries, this method often fails in complex scenarios, such as analyzing SEC 10-K filings. When a user asks about a company’s risk exposure, a standard vector search might return a paragraph about pricing and another about geographic dependencies, but it cannot inherently connect these fragments. The retriever lacks the "traversal" capability to move from a specific filing excerpt to the entity that filed it, the specific products affected, or the broader supply chain dependencies.
Compounding this retrieval issue is the problem of "statelessness." Most current AI agents operate without persistent memory, meaning every interaction begins from a blank slate. An agent has no record of a user’s previous inquiries, their specific preferences, or the entities that surfaced in prior sessions. This lack of continuity prevents AI from becoming a true "partner" in analytical tasks, forcing users to repeat context and instructions in every new session. The integration of Neo4j’s graph database technology into the Microsoft Agent Framework aims to solve both problems through distinct but complementary architectural responses.
The Microsoft Agent Framework: A Foundation for Orchestration
The Microsoft Agent Framework (MAF) is an open-source SDK and runtime designed for building AI agents in Python and .NET. It allows specialized agents to collaborate on complex tasks using a graph-based architecture that routes data between components. In this ecosystem, agents use "tools" to perform explicit actions—such as calling APIs or querying databases—and "context providers" to manage the flow of information.
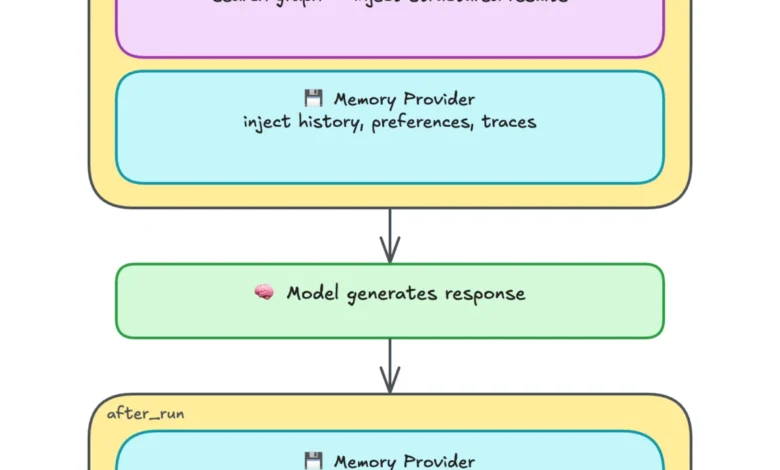
Neo4j’s new contributions function as context providers, operating around the "turn" of a conversation. Unlike tools, which must be explicitly called by the agent, context providers inject relevant knowledge before the AI model processes a prompt and persist information after it responds. This automated flow ensures that the agent is always equipped with the most relevant domain knowledge and historical context without requiring manual intervention from the developer or the user.
Graph-Enriched Retrieval: Moving Beyond Top-K Chunks
The first major component of this integration is the Neo4j Context Provider, a knowledge graph retriever designed to solve the "relational gap" in RAG. This provider utilizes Neo4j’s built-in vector search to find relevant text chunks but then immediately expands the search through graph relationships. For instance, in a financial analysis use case, the retriever can follow a path from a text chunk to a "Company" node, then to "Product" nodes, and finally to "Risk Factor" nodes.
This "GraphRAG" approach allows the agent to access structured context that lies beyond the immediate reach of a standard vector search. In a side-by-side comparison involving an analysis of Apple Inc., a standard vector-only search might identify that Apple faces "aggressive pricing." However, the graph-enriched search can simultaneously pull a structured list of specific risks—such as geographic exposure and short product life cycles—and link them directly to the company’s ticker (AAPL) and product catalog. By traversing these relationships, the agent provides a response that is not only more comprehensive but also more factually grounded in the structured metadata of the organization.
The technical implementation utilizes the neo4j-graphrag Python library, offering multiple retrieval patterns including basic vector search, hybrid search (combining vector and full-text), and Cypher-enhanced retrieval. The latter allows developers to write custom Cypher queries—the industry-standard graph query language—to define exactly which relationships the agent should explore after finding a relevant text chunk.
Persistent Memory: The Layered Approach to Continuity
While the retrieval provider offers domain expertise, the Neo4j Agent Memory provider offers continuity. This system enables an agent to learn from its own conversations, ensuring that "session twelve" benefits from the knowledge gained in "sessions one through eleven." The memory provider organizes information into three distinct temporal and structural layers:
- Short-Term Memory: This layer captures the immediate flow of conversation. It stores messages as nodes linked in a sequence, allowing the agent to understand the immediate context of a multi-turn dialogue.
- Long-Term Memory: This is perhaps the most critical layer for personalization. It extracts entities and relationships from every interaction and stores them using the POLE+O classification system (Person, Organization, Location, Event, and Object). This layer also records user preferences and subject-predicate-object triples, such as a company appointing a new CEO on a specific date.
- Reasoning Memory: This layer records the "how" of the agent’s work. It stores reasoning traces—the specific steps an agent took to solve a task, the tools it used, and the eventual outcome. When a similar task appears in the future, the agent can recall its previous approach, improving efficiency and accuracy.
A key feature of this memory system is its deduplication pipeline. When the system identifies "Apple" in one session and "Apple Inc." in another, it uses a combination of fuzzy string matching and embedding similarity to merge these mentions into a single entity via a "SAME_AS" relationship. This prevents the knowledge graph from becoming a fragmented collection of disconnected names, maintaining a "single source of truth" for the agent’s memory.
Industry Implications and the Path to Compounding Context
The integration of graph databases into agent frameworks represents a maturing of the AI industry. Analysts suggest that as enterprises move from pilot projects to production-ready AI, the demand for "stickiness" and "accuracy" will drive the adoption of GraphRAG and persistent memory. By combining the Neo4j Context Provider and Agent Memory, developers can create agents where the context "compounds" over time.
In the early stages of deployment, an agent relies heavily on the curated knowledge graph provided by the organization. However, as the agent interacts with users, the memory graph becomes denser. By the fiftieth session, the agent is no longer just a generic interface to a database; it is a specialized analyst that understands the specific risk categories its user prioritizes, the historical patterns of the companies being discussed, and the analytical frameworks that have proven successful in the past.
This evolution has profound implications for sectors such as legal, healthcare, and supply chain management, where the relationship between data points is often more important than the data points themselves. In a supply chain context, for example, an agent could use these providers to not only identify a delay in a specific shipment but also to recall a previous discussion about a backup supplier and analyze the geographic risk of the new route based on historical data stored in its memory.
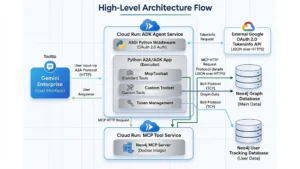
Implementation and Deployment on Azure
For organizations looking to implement these capabilities, the integration is designed to be a seamless "upgrade path" rather than a complete architectural overhaul. The Neo4j context providers are compatible with existing MAF workflows and can be deployed on Microsoft Azure, utilizing Azure Foundry for production-grade tracing and metrics.
The setup process involves configuring the Neo4jContextProvider with a specific vector index and retrieval query, then attaching it to the agent’s context_providers list. Simultaneously, the Neo4jMicrosoftMemory provider is initialized with a session ID and extraction settings. Once attached, the agent automatically begins the process of retrieving graph-enriched data and writing new memories to the Neo4j database on every turn.
Final Analysis: The Shift Toward Relational Intelligence
The release of the Neo4j context providers for the Microsoft Agent Framework addresses the two most significant hurdles in modern AI development: the "context window" limitation and the "statelessness" of LLMs. By providing a structured way to navigate complex data and a persistent way to store human-AI interactions, Neo4j and Microsoft are enabling a new class of "relational" AI.
These agents do not just "search" for information; they "understand" the environment in which that information exists. As the memory of these agents grows from sparse nodes to a dense web of deduplicated entities and reasoning traces, the value they provide to the enterprise will increase exponentially. The era of the "blank slate" AI is ending, replaced by a generation of agents that remember, relate, and reason with increasing sophistication over time.


{kind=link}