The landscape of artificial intelligence is rapidly evolving, with Large Language Models (LLMs) at the forefront of this transformation. As organizations increasingly leverage these powerful tools for a myriad of applications, from advanced chatbots to complex data analysis, the challenge of efficiently serving them at scale becomes paramount. Unlike traditional web services, APIs, or databases, the unique architectural demands of LLMs necessitate a fundamental rethinking of load balancing strategies. At the heart of this difference lies the concept of prompt caching, a technique that dramatically enhances performance and cost-efficiency but poses significant challenges for standard load balancing approaches.
Prompt caching has emerged as a critical optimization for LLM inference. By storing and reusing previously computed parts of a prompt, commonly referred to as the Key-Value (KV) cache, LLMs can drastically reduce the computational overhead associated with processing repetitive or similar inputs. This can translate into substantial savings, with estimates suggesting input token costs can be slashed by 50-90%. Furthermore, prompt caching significantly improves the user experience by reducing Time to First Token (TTFT) latency, sometimes by as much as 80%. However, these impressive gains are contingent on a crucial factor: the incoming request must land on an inference engine replica that already possesses the relevant portion of the prompt cached.
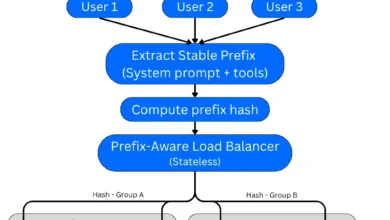
The limitations of conventional load balancing methods, such as naive round-robin distribution across multiple replicas, become starkly apparent in this context. Under such a scheme, where a request has an equal probability of being directed to any of the N available replicas, the chance of hitting a replica with the desired cached prefix is a mere 1/N. This means that the cache hit rate, the very mechanism that makes caching so attractive at a single instance, degrades almost linearly as the fleet of inference engines grows. Consequently, achieving the full potential of prompt caching at scale requires a departure from established load balancing paradigms and an embrace of specialized routing mechanisms designed to preserve cache efficiency.
The Engine of Inference: Understanding LLM Serving Infrastructure
To deploy LLMs at a scale that meets the demands of modern applications, specialized inference engines are indispensable. These sophisticated software frameworks abstract away the intricate complexities of serving LLMs, optimizing the utilization of underlying hardware, particularly Graphics Processing Units (GPUs). They are engineered to handle high concurrency and can be customized to accommodate a diverse range of inference workloads, from the rapid-fire responses of real-time chat completions to the more deliberate processing required for long-form document summarization. Prominent examples of these inference engines include vLLM, SGLang, and NVIDIA’s TensorRT, each offering unique strengths and optimizations.
The fundamental process of LLM inference, regardless of the specific engine employed, follows a generally consistent pattern when initiated by an HTTP request. This process involves several key stages:
- Request Ingestion: The inference engine receives an incoming request, typically containing a prompt or a series of prompts.
- Tokenization: The input text is broken down into smaller units called tokens, which the LLM can process.
- Prefill Stage (Initial Prompt Processing): For the initial tokens of a prompt, the engine performs a computation-intensive "prefill" operation. This involves processing the entire sequence of input tokens to generate the initial KV cache. This stage is particularly demanding in terms of computational resources.
- KV Cache Generation and Storage: During the prefill stage, the engine computes and stores the KV cache. This cache contains intermediate representations of the prompt’s embeddings, crucial for accelerating subsequent token generation.
- Decoding Stage (Token Generation): For subsequent tokens, the LLM uses the KV cache to predict the next token. This stage is generally less computationally intensive per token but can be memory-bandwidth bound.
- Output Generation: The generated tokens are assembled to form the LLM’s response.
- Response Transmission: The final output is sent back to the user or application.
Optimizations and KV Cache Significance:
For conversational AI applications, where user interactions can involve extensive dialogue histories, sending the entire conversation history with every new message is highly inefficient. This is where the KV cache plays a pivotal role. By reusing previously computed KV caches for earlier parts of the conversation, the "prefill" stage for new messages can be significantly reduced or even bypassed. This reuse directly translates into a lower TTFT, leading to a more fluid and responsive user experience. Without effective KV cache management and retrieval, the performance gains offered by LLMs would be severely diminished, particularly in interactive scenarios.
Navigating the Maze: Routing Strategies for Homogeneous Inference Instances
When deploying multiple instances of the same LLM model, referred to as homogeneous instances, a critical decision point arises: how to route incoming requests to these instances. Several standard load balancing strategies are commonly considered, each with its own set of advantages and disadvantages:
-
Random or Round Robin: This approach distributes requests either randomly among the available inference engines or in a sequential, round-robin fashion. While simple to implement, its primary drawback is suboptimal performance. Random routing, in particular, fails to leverage the crucial benefit of KV caching. By directing requests to different engines with each new query, it significantly hinders the effective utilization of engine-specific KV caches, leading to missed opportunities for performance gains and inconsistent results.
-
Consistent Hashing (Sticky Sessions): This strategy aims to maintain session affinity by ensuring that requests from the same user consistently land on the same inference engine. This is often achieved through mechanisms like "sticky sessions" or routing based on a
user_id. While an improvement over purely random routing, especially for long conversational workloads where sustained cache hits are beneficial, it still faces a significant challenge: the first request from a new user. This initial request could be routed to any engine, potentially one that lacks the necessary prompt prefix cached, thus negating the caching advantage for that specific interaction. -
Cache-Aware Load Balancing: This strategy represents a more sophisticated approach, aiming to route requests to the inference engine that possesses the most relevant cached prompt prefix. The goal is to maximize the probability of a cache hit. However, if the load across the engines becomes uneven, the strategy dynamically shifts to prioritize load balancing, aiming to minimize imbalance. A key limitation of this approach is that routing decisions are often made based on the request alone, without direct feedback from the engines about their actual cache status. If an engine’s cache has been invalidated or purged since the last routing decision, the decision might be inaccurate, leading to a cache miss.
The evolution of load balancing for LLMs has seen a progression from these foundational strategies to more advanced techniques. Cache-aware load balancing, in its standard form, is a significant step forward. A more sophisticated iteration, known as precise prefix cache-aware routing, takes this a step further. This advanced strategy involves the router actively capturing KV cache events emitted by the inference engines. This real-time information allows for highly informed routing decisions, specifically directing requests to the engine that offers the greatest overlap with its existing prefix cache.
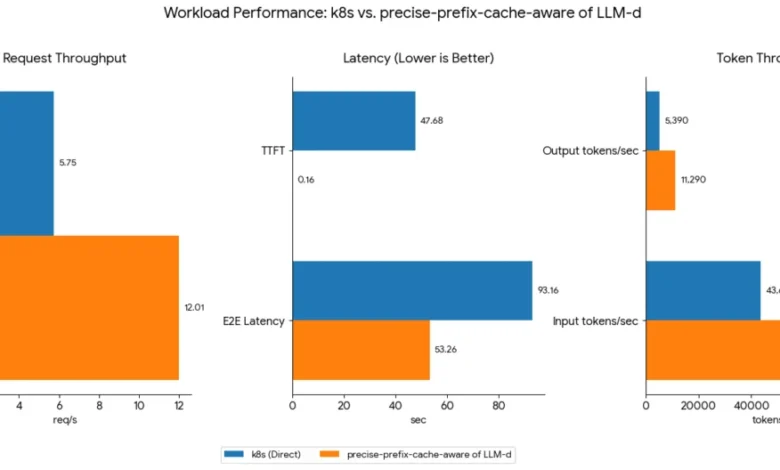
The impact of these routing strategies on LLM inference performance can be substantial. Benchmarking efforts, such as those conducted by the LLM-d community, have demonstrated significant improvements. For instance, a comparison between a precise-prefix-cache-aware routing strategy and a standard Kubernetes service employing a round-robin or random policy has shown throughput improvements of up to 108% for the same hardware configuration and workload. These benchmarks, available on the LLM-d routing benchmark page, underscore the critical role of intelligent routing in unlocking the full potential of LLM serving infrastructure.
The Mechanics of Cache-Aware Routing
At its core, cache-aware routing relies on efficient data structures that facilitate rapid prefix matching. A Radix tree, also known as a digital tree or prefix tree, is a common choice for this purpose. A separate radix tree is maintained for each inference engine instance, acting as a localized index of cached prompt prefixes.
When a new request arrives, its prompt is extracted. The system then efficiently queries all the instance-specific radix trees to identify the one that exhibits the longest matching prefix with the incoming prompt. This engine is then selected to handle the request. Subsequently, the new prompt is inserted into the radix tree of the chosen instance, ensuring that it can be leveraged for future routing decisions.
To prevent the radix trees from growing indefinitely and consuming excessive memory, a Least Recently Used (LRU) policy is typically implemented for purging its contents. This ensures that older, less frequently accessed cache entries are removed to make space for new ones.
.png)
Furthermore, a purely cache-centric routing strategy can sometimes lead to load imbalances. To address this, the routing design incorporates a load-balancing mechanism that employs a balance threshold. This dynamic approach allows the system to fluidly switch between prioritizing cache-aware routing and pure load balancing, depending on the current distribution of workload across the inference engines. This ensures that neither cache efficiency nor even load distribution is compromised.
A limitation of some current cache-aware routing designs is that they store the entire prefix cache state within the router itself, without direct, real-time feedback from the individual inference engines regarding their actual prefix cache status. This disconnect can lead to inaccuracies in routing decisions. Inaccuracies can manifest in two primary ways:
- Cache Invalidation: An engine might have its KV cache invalidated or purged due to resource constraints or LRU policies. However, the router, unaware of this change, might still route a request to that engine based on outdated information, leading to a cache miss.
- Stale Cache State: The router’s representation of an engine’s cache might be slightly out of sync due to the time lag in updating its internal state. This can result in routing decisions based on a cache that is no longer precisely representative of the engine’s current capabilities.
Precise Prefix Cache-Aware Routing: The Next Frontier
To overcome the inaccuracies inherent in simpler cache-aware methods, a more precise approach is often necessary: precise prefix cache-aware routing. This advanced algorithm significantly enhances routing accuracy by establishing direct communication channels between the router and the inference engines.
In this refined model, the router receives up-to-date KV cache information directly from each engine via KV cache events. This real-time data feed allows the router to make highly informed routing decisions, ensuring that requests are directed to engines that demonstrably possess the most relevant cached data.
This method differs from simpler cache-aware routing in its processing flow. Before performing the prefix match using a radix tree, the router must first tokenize the input text prompt. While this adds a computational step during the routing process, the overall approach yields substantial speed advantages and, crucially, offers much greater precision. Tokenization is a comparatively faster operation than the computationally intensive prefill or decoding phases of LLM inference.
To ensure high availability (HA) and enable independent scaling of the router layer itself, external solutions can be employed. Technologies like Redis can serve as a robust backend for storing and managing the router’s state. Alternatively, a mesh architecture backed by Conflict-Free Replicated Data Types (CRDTs) can provide a highly resilient and scalable solution. This CRDT-based approach allows each router instance to maintain a replicated data structure (effectively, the "tree" of cached prefixes) such that they can independently handle KV events and process requests without requiring centralized coordination or maintaining individual, separate trees. This inherent distributed capability is key to enabling the horizontal scaling of the router layer, ensuring it can keep pace with the growing demands of LLM inference.
Disaggregated Serving: Deconstructing LLM Inference for Extreme Sequence Lengths
For workloads involving exceptionally long sequences, a more advanced architectural pattern known as disaggregated serving comes into play. This approach separates the LLM inference process into distinct stages, typically a "prefill" stage and a "decode" stage, which can be handled by specialized hardware and software components.
The efficiency of these stages is often understood through the lens of arithmetic intensity, defined as the ratio of arithmetic operations to memory operations. This ratio is a critical determinant of whether an operation is primarily constrained by computational power (compute-bound) or memory access speed (memory-bound).
-
Prefill Stage (No Batching): This initial processing of the prompt is highly compute-bound. It involves significant matrix multiplications and other arithmetic operations to generate the KV cache. Therefore, hardware with higher TFLOPs (teraflops) is most beneficial for accelerating this stage.
-
Decode Stage (Per-Token Generation): Once the KV cache is established, the generation of subsequent tokens becomes more memory-bandwidth bound. The engine needs to rapidly access and process the KV cache data to predict the next token. Hardware with high memory bandwidth is therefore crucial for optimizing this stage.
This difference in computational characteristics means that optimal performance often requires selecting hardware tailored to the specific needs of each stage. High TFLOPs for prefill, and high memory bandwidth for decode.
A critical aspect of disaggregated serving is the efficient and rapid transfer of the calculated KV cache from the prefill engines to the decode engines. This transfer must be executed with maximum speed, minimizing any additional memory movement that could introduce latency. Several high-performance solutions exist for this KV cache transfer, including NCCL (Nvidia), RCCL (AMD), NVIDIA NIXL, Mooncake TE (Transfer Engine), and UCCL P2P. Comprehensive benchmarks comparing the performance of these KV cache transfer engines are available, providing valuable insights for architectural decisions.
While disaggregated serving offers potential benefits for extreme workloads, it is not a universally optimal solution. The overhead associated with KV cache transfer, even with advanced technologies like RDMA, introduces a degree of latency and bandwidth limitation compared to on-GPU memory access. Consequently, disaggregated serving is generally recommended for very large models with demanding workloads, particularly those involving exceptionally long sequences, such as an Input Sequence Length (ISL) of 100,000 tokens and an Output Sequence Length (OSL) of 1,000 tokens. In such scenarios, the ratio of prefill to decode nodes should be dynamically adjusted based on the specific ISL/OSL workload characteristics to maintain optimal performance.
For scenarios with smaller ISL, the benefits of P/D dis-aggregation may be outweighed by the transfer overhead. In these cases, a single worker can efficiently handle both the prefill and decode operations. A common practice is to implement a threshold that dynamically switches between disaggregated and non-disaggregated serving modes, ensuring the most efficient architecture for the given workload.
The Future of LLM Serving: Towards Shared Cache Layers
The routing strategies discussed thus far primarily operate under the assumption that the KV cache state remains local to individual inference engine replicas. The logical next step in the evolution of LLM serving, and an area of active industry development, is the concept of a shared cache layer. Such a layer would be accessible across all replicas, potentially backed by a high-bandwidth CPU DRAM pool. This would allow any replica to serve a cache hit, regardless of which replica originally computed and stored the cached data.
However, the primary challenge in realizing a truly shared cache layer lies in latency. Moving KV tensors across a network boundary, even with high-speed interconnects like RDMA, is inherently slower than reading from local GPU VRAM. Until this latency tradeoff can be resolved to acceptable levels for production workloads, strategies like session affinity and precise prefix-aware routing remain the practical state of the art for optimizing LLM inference efficiency at scale. The ongoing research and development in this area signal a continuous push towards more performant, cost-effective, and scalable LLM serving solutions.
Disclaimer: Performance metrics and savings (including TTFT and token costs) are based on specific benchmarks and configurations; actual results may vary and are not guaranteed. References to third-party tools are for informational purposes only and do not constitute an endorsement. This content is provided "as-is" for educational use and does not constitute a technical warranty or a binding Service Level Agreement (SLA).


{kind=link}