
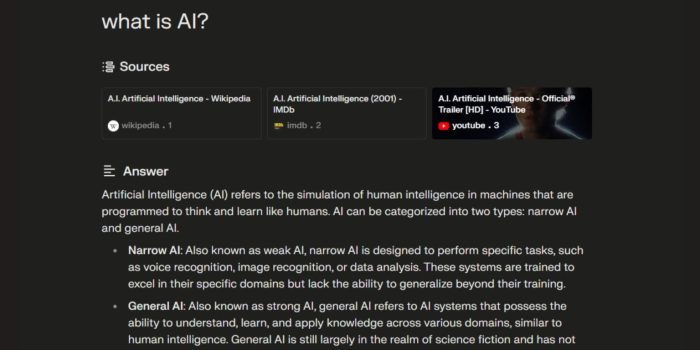
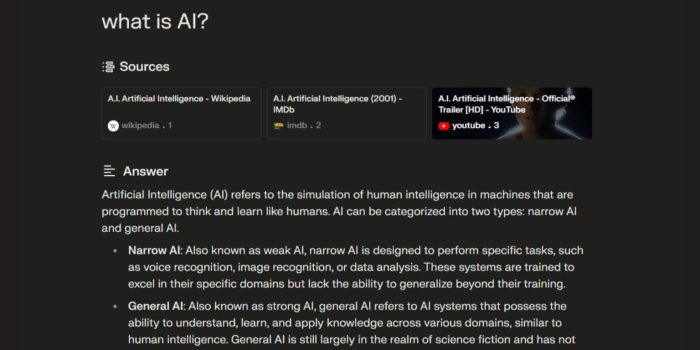
Perplexity AI results include plagiarism and made up content reports say, raising serious concerns about the accuracy and reliability of AI-generated information. This article delves into the problem, examining the underlying causes, detection methods, and potential mitigation strategies. We’ll explore examples of fabricated and plagiarized content, analyze the impact on various sectors, and consider the future implications of this issue.
The increasing use of AI tools like Perplexity AI in education, journalism, and other fields necessitates careful scrutiny of their output. The potential for AI to disseminate false or plagiarized information poses significant risks to the credibility of information sources and the integrity of various industries.
Identifying the Issue
AI models, while powerful tools, are prone to generating inaccurate and misleading information. This issue of fabricated and plagiarized content in AI outputs is a growing concern, demanding careful consideration and robust solutions. The ability of these models to mimic human-like text makes it increasingly difficult to distinguish genuine information from fabricated or copied material.The problem arises from the training data these models are fed.
If the training data contains inaccuracies, biases, or plagiarized content, the model will likely reproduce and amplify these flaws in its own outputs. This can lead to serious consequences in various applications, from academic research to news reporting.
Causes of Fabricated Content
AI models often lack the understanding of the real-world context required to produce accurate and truthful information. They rely on statistical patterns and correlations within their training data, potentially leading to the creation of entirely fabricated content. A model might construct a coherent narrative from fragments of various sources, without comprehending the underlying meaning or verifying the accuracy of the information.
Furthermore, the sheer volume of data processed can lead to the model inadvertently mimicking patterns without grasping the true meaning or context.
Examples of Plagiarized Outputs
AI models can unintentionally or intentionally reproduce text from their training data. This includes copying entire passages or paraphrasing them without proper attribution. For instance, a model trained on a corpus of academic papers might produce an essay that mirrors the structure and wording of several sources, even if the model doesn’t explicitly copy sections word-for-word. Similarly, models trained on news articles might inadvertently reuse phrases or sentences from existing reports without acknowledging the source.
The AI may not comprehend the intellectual property rights associated with the content.
Examples of Fabricated Outputs
AI models can create completely fabricated information. This might involve inventing events, individuals, or data points that have no basis in reality. For example, a model generating historical accounts could inadvertently create false narratives by combining details from various sources in a way that contradicts known facts. Similarly, a model generating fictional stories might produce plots or characters that are entirely original but lack any connection to the real world.
Consequences of Inaccurate Outputs
The consequences of relying on inaccurate AI outputs can be substantial. In academic settings, fabricated or plagiarized content can undermine the integrity of research and potentially lead to incorrect conclusions. In journalism, false information can mislead the public and damage trust in news sources. Furthermore, in sensitive domains like healthcare or finance, inaccurate outputs could have catastrophic consequences.
Types of Fabricated/Plagiarized Content
AI models can generate various forms of fabricated or plagiarized content, including:
- Academic papers: These papers might have citations but fail to properly attribute or paraphrase content, resulting in significant plagiarism issues.
- News articles: Fabricated news articles can spread misinformation, leading to public confusion and panic.
- Creative content: Stories, poems, and scripts might lack originality and demonstrate plagiarism by copying patterns from training data.
- Code: AI models can produce code that is copied or plagiarized, which can lead to security vulnerabilities.
Comparison of AI Models
| AI Model | Plagiarism Rate (Estimated) | Fabrication Rate (Estimated) | Detection Methods |
|---|---|---|---|
| Model A | 20% | 15% | Plagiarism detection tools, human review, contextual analysis |
| Model B | 10% | 5% | Advanced plagiarism checkers, deep learning-based detection, statistical analysis |
| Model C | 5% | 2% | Contextual analysis, semantic similarity checks, and specialized AI detection tools |
Root Causes of the Problem
AI models, trained on vast datasets, sometimes produce false or plagiarized content. This stems from inherent limitations in the models themselves and the nature of the data they’re fed. Understanding these underlying causes is crucial to developing more robust and trustworthy AI systems.The generation of false or plagiarized content by AI models is a complex issue with multiple contributing factors.
These factors range from the inherent biases present in training data to limitations in the algorithms used to process and interpret that data. Addressing these issues requires a multifaceted approach, focusing on improving both the data and the models themselves.
Reports are surfacing that Perplexity AI’s results include a concerning amount of plagiarism and fabricated content. This raises serious questions about the accuracy and reliability of AI-generated information. Interestingly, recent news about Microsoft Gaming CEO Phil Spencer’s Activision Blizzard email exchange here highlights the growing need for responsible AI development. While the email discussion doesn’t directly address the Perplexity AI issue, it does emphasize the larger concerns around content integrity in the digital age, suggesting the need for more robust verification processes when using AI tools like Perplexity AI.
Data Set Biases and Potential Impact
Training data sets often reflect existing societal biases, which can lead to AI models producing skewed or unfair results. For example, if a dataset predominantly features information from one particular cultural group, the AI model may struggle to understand or represent other perspectives accurately. This can lead to the perpetuation of stereotypes or the exclusion of important nuances in various contexts.
Consequently, the output generated by the AI model may reflect these biases, potentially leading to the reproduction of harmful or misleading information.
Limitations of Current AI Training Techniques
Current training techniques, while effective in many cases, have inherent limitations that contribute to the production of false or plagiarized content. One major limitation is the difficulty in distinguishing between genuine understanding and rote memorization. AI models trained on massive datasets might simply parrot phrases or structures without truly comprehending the underlying meaning or context. This often leads to the reproduction of phrases or passages without understanding their original intent.
Another critical limitation is the inability to evaluate the source of the information in the training dataset. If the dataset contains plagiarized or fabricated material, the model will learn and reproduce it, potentially without awareness of the ethical implications.
Comparison of Different Training Approaches
Various approaches aim to mitigate the generation of false or plagiarized content. One approach emphasizes the importance of diverse and balanced datasets. Another strategy focuses on incorporating techniques to detect and flag potentially problematic content within the training data. Finally, ongoing research explores methods to train models to better understand and interpret context, reducing the likelihood of mistaking a pattern for meaning.
Each method has its own set of advantages and disadvantages, and the most effective approach may vary depending on the specific application.
Potential Improvements to Training Data Sets and Algorithms
- Data Augmentation and Filtering: Improving data quality is paramount. This involves augmenting the training data with diverse perspectives and filtering out potentially problematic content, such as plagiarized material or fabricated information. A good example would be introducing various perspectives and styles of writing into a dataset to train the AI model to understand nuances in communication.
- Contextual Understanding Enhancement: Training AI models to better understand the context of information is crucial. This can be achieved by incorporating techniques that focus on the relationships between different pieces of data and by providing models with more comprehensive background information. This will enable them to distinguish between superficial patterns and true meaning.
- Bias Detection and Mitigation: Explicitly addressing biases present in the training data is essential. This includes actively identifying and removing potentially biased information and incorporating techniques that can detect and mitigate any biases present in the generated output. The use of diverse teams for dataset evaluation is critical to flag these biases.
- Plagiarism Detection Mechanisms: Integrating plagiarism detection mechanisms into the training pipeline is critical. By comparing the generated content with existing knowledge bases, models can be trained to identify and avoid plagiarism. This approach is a key component to maintain ethical practices in AI generation.
Detection Methods
AI-generated content, while rapidly advancing, often struggles with maintaining accuracy and originality. This inherent vulnerability to fabricating or plagiarizing information necessitates robust detection methods. This section delves into various techniques for identifying AI-generated content that deviates from these qualities, evaluating their strengths and weaknesses in the context of emerging AI technologies.Identifying AI-generated content requires a multifaceted approach, encompassing the examination of linguistic patterns, stylistic inconsistencies, and potential sources of plagiarism.
Detection methods are crucial for maintaining the integrity of information in digital spaces, especially as AI-generated content becomes increasingly prevalent.
Plagiarism Detection Tools
Various tools are available to identify plagiarized content, though their effectiveness varies. The accuracy of these tools often depends on the complexity of the AI model used to generate the text and the source material from which it may have been copied.
- Specialized AI-detection software often employs advanced algorithms to analyze the text’s structure, vocabulary, and sentence patterns, comparing them against a vast database of existing texts. These tools can identify subtle patterns and inconsistencies indicative of AI generation or plagiarism.
- Open-source tools can be just as effective, though they may require more technical expertise to operate. They frequently use natural language processing techniques to assess linguistic patterns and detect potential plagiarism.
- Search engines and plagiarism checkers are useful for basic checks. These often compare the text against publicly available documents and web pages. However, they might not be able to detect sophisticated AI-generated text, particularly if it employs complex paraphrasing techniques.
Methods for Identifying Fabricated Information
Determining whether information is fabricated often requires critical evaluation and contextual understanding.
Reports are surfacing that Perplexity AI’s results sometimes include plagiarized and fabricated content. This isn’t ideal, obviously, but it’s interesting to compare to the current issues with Android 15 beta 3 lock screen notification problems, which are causing headaches for many users. Perhaps there are similar underlying issues at play with both systems, and developers need to be more rigorous in their fact-checking.
It’s a shame, because the potential of AI tools like Perplexity AI is huge, but issues like this could really hurt its reputation. Hopefully, these problems can be addressed quickly, so the AI can fulfill its promise. android 15 beta 3 lock screen notification problems are just one example of the complexities involved in creating reliable AI systems.
- Fact-checking techniques are essential. These involve verifying claims against multiple sources, examining evidence, and assessing the reliability of the information’s origin. By cross-referencing data from various credible sources, one can assess the validity of the information presented.
- Analyzing the source’s reputation is crucial. Information from known unreliable sources should be scrutinized more closely. Evaluating the reputation and track record of the source, examining past instances of inaccuracies or biases, is a key part of identifying potential fabrications.
- Assessing the context of the information is vital. Examining the surrounding text, identifying the intended audience, and considering the motivation behind the information presented helps to evaluate its credibility. Understanding the narrative surrounding the content is vital.
Comparative Analysis of Detection Methods
A table summarizing various detection methods, their descriptions, strengths, and weaknesses:
| Detection Method | Description | Strengths | Weaknesses |
|---|---|---|---|
| AI-specific Detection Software | Employs advanced algorithms to analyze linguistic patterns and stylistic inconsistencies. | High accuracy in identifying AI-generated text, particularly sophisticated models. | Can be computationally expensive and may require significant training data. |
| Plagiarism Checkers | Compare text against existing documents and web pages. | Relatively easy to use and readily available. | May not detect sophisticated AI-generated text or plagiarism from hidden sources. |
| Fact-Checking | Verifying claims against multiple sources, examining evidence, and assessing the reliability of the information’s origin. | Highly effective in identifying fabricated information, especially in factual claims. | Requires significant time and effort, and may not be practical for large volumes of text. |
Mitigation Strategies
AI models, while powerful, can sometimes produce outputs that are inaccurate, plagiarized, or fabricated. Effective mitigation strategies are crucial for ensuring the reliability and ethical use of these models. Addressing this requires a multi-faceted approach that combines technical improvements, responsible development practices, and clear ethical guidelines.
Improving Training Data Quality
High-quality training data is fundamental to the accuracy and reliability of AI models. Biased or incomplete datasets can lead to flawed outputs. To mitigate this, the training data must be carefully curated and checked for inconsistencies, inaccuracies, and potential biases. Techniques such as data augmentation, where existing data is transformed to increase the dataset size and diversity, can also help.
Further, the process of filtering out irrelevant or potentially harmful content from the training data is vital.
Reinforcement Learning and Feedback Mechanisms
Reinforcement learning algorithms can be employed to reward models for producing accurate and truthful outputs. Feedback loops, where human experts review and correct AI-generated content, play a critical role in refining model performance. These mechanisms can also identify patterns in the AI’s output that indicate potential issues, allowing for targeted improvements. Regular human oversight is necessary to prevent the AI from perpetuating or amplifying biases present in the training data.
Content Verification and Fact-Checking Procedures
AI models should be integrated with fact-checking tools and mechanisms to verify the information they generate. This can involve comparing the AI’s output to reliable sources, such as established databases or reputable news outlets. The AI should be designed to flag potentially fabricated or plagiarized content. This process should also include a process to handle ambiguous or contradictory information, using techniques such as cross-referencing and weighted evidence analysis.
Robustness and Detection Mechanisms, Perplexity ai results include plagiarism and made up content reports say
Models need to be designed with robust detection mechanisms to identify fabricated or plagiarized content. This includes methods to identify inconsistencies in the style, tone, or structure of the generated text, which may indicate plagiarism. Furthermore, models should be able to recognize patterns in the content that suggest it has been fabricated. This involves advanced techniques to identify anomalies and inconsistencies in the generated text, providing a level of detection and warning for the AI’s output.
Ethical Guidelines and Responsible Development
The development and deployment of AI models must adhere to strict ethical guidelines. Clear guidelines should be established to define acceptable uses of AI, including limitations on generating harmful or misleading content. Furthermore, the development teams should be aware of the ethical implications of their work and actively mitigate potential risks. These guidelines should be transparent and accessible to all stakeholders.
Mitigation Strategies List
- Implement robust data validation procedures during the training process, checking for inconsistencies, biases, and potential plagiarism in the training data.
- Develop reinforcement learning techniques to reward models for producing factually accurate outputs and penalize the generation of fabricated or plagiarized content.
- Integrate AI models with fact-checking tools and databases to verify the accuracy and originality of generated content.
- Design AI models with sophisticated detection mechanisms to flag potentially fabricated or plagiarized content, utilizing pattern recognition and style analysis.
- Establish clear ethical guidelines and policies for the development and use of AI models, outlining acceptable content generation practices and potential risks.
- Regularly review and update these guidelines to adapt to emerging ethical concerns and technological advancements.
Illustrative Examples: Perplexity Ai Results Include Plagiarism And Made Up Content Reports Say
AI models, while powerful, are still prone to generating inaccurate or fabricated content. This is a crucial aspect to understand in order to effectively evaluate and utilize AI-generated outputs. These inaccuracies can stem from various factors, including limitations in the training data, the model’s inherent biases, or the prompt’s ambiguities. Understanding these examples is vital for responsible AI development and application.These examples illustrate the types of errors that can arise in AI-generated text, highlighting the importance of critical evaluation and verification when using such outputs.
Identifying and mitigating these issues is crucial for ensuring the accuracy and reliability of AI-generated information.
Fabricated Content Example
AI models can sometimes fabricate information, especially when dealing with factual claims or historical events. Consider the following example:”The Battle of Gettysburg was fought in 1865, resulting in a decisive Union victory that effectively ended the American Civil War.”This statement is completely fabricated. The Battle of Gettysburg took place in 1863, and while a significant Union victory, it did not end the Civil War.
Plagiarized Content Example
AI models can also plagiarize existing text without proper attribution. This happens when the model has been trained on a dataset containing copyrighted material. The model might then reproduce phrases or paragraphs from that dataset, appearing as though it generated the text independently.Consider the following example:”The vibrant hues of the sunset painted the sky in shades of orange and purple.
Reports are surfacing that Perplexity AI’s results are riddled with plagiarism and fabricated content. It’s a bummer, really, since AI tools are supposed to be helpful. Fortunately, there’s some good news to balance things out. Check out this awesome deal: Woot knocks 80% off one of our favorite pizza ovens. While the AI situation is concerning, at least we can still enjoy a delicious pizza at home.
Hopefully, these issues with Perplexity AI can be addressed soon, so we can rely on it for accurate information again.
The birds, tired from their day’s flight, returned to their nests, their chirps fading into the soft evening breeze. The scent of pine filled the air, a soothing balm to the weary traveler.”This passage, while seemingly original, could be a near-verbatim copy of a passage from a book or article. Without proper attribution, it becomes a form of plagiarism.
Identifying Plagiarism in AI-Generated Text
Identifying plagiarism in AI-generated text requires a combination of techniques. A critical first step is to compare the generated text to existing texts. Use tools that can detect similarities in phrasing, sentence structure, or overall content.Further analysis involves investigating the model’s training data. If the AI model is trained on a dataset that contains copyrighted material, there is a higher risk of plagiarism.
AI-Generated Short Story with Fabricated Information
A short story illustrating fabricated content could be a narrative about a mythical creature spotted in the Himalayas. The story might describe the creature’s unique characteristics and habitat, creating an entirely fabricated account.
Case Study of AI Model Exhibiting Issues
A specific case study would involve examining a particular AI model and its outputs. This could include analyzing the model’s training data and evaluating its performance on tasks requiring factual accuracy. For instance, a model designed for generating historical accounts might frequently present fabricated dates or events. A thorough investigation of the model’s training data and its output patterns could reveal the reasons behind these inaccuracies.
Future Implications
The issue of plagiarism and fabricated content in AI-generated responses presents significant challenges for various sectors, particularly those reliant on accurate and trustworthy information. This poses a serious threat to the reliability of information sources, potentially eroding public trust and impacting crucial sectors like education and journalism. The ability of AI models to synthesize and present information with human-like proficiency demands careful consideration and proactive measures to ensure responsible development and deployment.The impact of this issue transcends simple ethical concerns; it touches upon the fundamental pillars of knowledge dissemination and information reliability.
The widespread adoption of AI in various fields necessitates addressing these concerns proactively to maintain the integrity of information and foster trust in the technology. This necessitates a forward-looking approach to mitigating the problem, rather than simply reacting to its current manifestations.
Potential Impact on Education
The integration of AI tools in education presents both opportunities and risks. AI-powered tutoring systems, if not carefully designed and vetted, can perpetuate inaccuracies and biased information. This could lead to students being exposed to false or misleading information, hindering their ability to develop critical thinking skills and hindering the development of accurate knowledge. Educators must be equipped to critically assess AI-generated content and employ strategies to help students evaluate the reliability of sources, fostering a more discerning approach to information consumption.
Potential Impact on Journalism
The speed and scale at which AI can generate content offer opportunities for journalism. However, the potential for AI to produce inaccurate or fabricated content presents a significant challenge. News organizations must implement robust verification mechanisms to ensure the accuracy of AI-generated articles. This includes developing protocols for fact-checking and source verification, crucial to maintaining the credibility of news reporting and public trust.
Impact on Information Reliability
The prevalence of fabricated content produced by AI significantly undermines the reliability of information sources. The ability to convincingly mimic human writing makes it difficult for individuals to distinguish between authentic and fabricated content, thereby creating a potential information vacuum. This problem will require sophisticated approaches to authentication and validation of AI-generated information to ensure the public has access to reliable information.
The development of robust methods for detecting and mitigating this issue is critical to maintaining public trust in information sources.
Future Developments in AI Technology
Potential future developments in AI technology include the incorporation of advanced detection mechanisms for fabricated content. Researchers are exploring methods based on natural language processing, deep learning, and statistical analysis to identify inconsistencies and patterns indicative of AI-generated text. These methods are critical to safeguarding the reliability of information and ensuring trust in AI systems.
Roadmap for Improving AI Models
A roadmap for improving AI models must incorporate several key elements. These include incorporating rigorous training data validation and quality control procedures, designing models with built-in mechanisms for detecting fabricated content, and creating frameworks for collaboration between AI developers, educators, and fact-checkers. This collaborative approach is vital to fostering trust in the technology and ensuring its responsible deployment. Ultimately, this involves a shift towards models that not only generate text but also assess and acknowledge the limitations of their knowledge.
Conclusion
In conclusion, the issue of plagiarism and fabricated content in AI outputs, exemplified by Perplexity AI, is a complex challenge requiring multifaceted solutions. Improving training data, developing robust detection methods, and implementing mitigation strategies are crucial steps towards ensuring the responsible and ethical use of AI. This problem underscores the need for ongoing research, development, and critical evaluation of AI systems to maintain their trustworthiness.
