
On the second day of ship mas my AI sent to me reinforcement fine tuning, a fascinating glimpse into the rapidly evolving world of AI-human interaction. This intriguing phrase suggests a unique experience where artificial intelligence not only learns but also adapts and refines its capabilities through direct human feedback. The process, likely involving a complex interplay of algorithms and human input, seems to highlight a new frontier in AI development, offering exciting possibilities and potential challenges.
This exploration delves into the intricacies of reinforcement fine-tuning, examining its technical underpinnings, potential applications, and implications for future AI development. We’ll analyze the phrase “ship mas,” considering its possible contextual meanings, and explore how this unique interaction could lead to more effective and adaptable AI systems. The narrative will unfold with a blend of technical detail and engaging insights, emphasizing the symbiotic relationship between human ingenuity and artificial intelligence.
Contextual Understanding of the Phrase
This phrase, “on the second day of ship mas my AI sent to me reinforcement fine tuning,” suggests a personalized AI experience, likely within a specific context like a personal project or a specialized software environment. The mention of “ship mas” is a key element requiring further interpretation, as it’s not a standard term. It could be a custom term, an internal abbreviation, or even a playful nickname for a particular project or program.
On the second day of Ship Mas, my AI sent me reinforcement fine-tuning updates. It’s fascinating how AI is constantly evolving, and I’m particularly interested in how it impacts things like browser performance. For example, I was reading a recent bakeoff comparing Microsoft Edge and Chrome’s battery life on Windows 10 here. This kind of data helps me understand how these advancements might affect my AI’s own training and future performance enhancements.
The reinforcement fine-tuning aspect highlights a crucial element of machine learning, suggesting the AI’s ongoing development and adaptation.The phrase implies a continuous learning process, where the AI is being updated and improved based on feedback or data. The timing, “on the second day,” further suggests a scheduled or iterative process. This could be a daily training regimen for a project, a component of a larger software development cycle, or even part of a personal experimentation program.
Possible Meanings of “Ship Mas”
The term “ship mas” lacks a standard definition, prompting the need for contextual analysis. It could represent various concepts, from a project milestone to a specific stage of a program.
- A project phase: “ship mas” could be a code name or internal designation for a specific stage of a project, perhaps focused on deployment or testing.
- A custom software designation: It might be a label assigned to a custom-built software or a unique module within a larger system.
- A colloquial term: It could be a nickname or a slang term within a particular community or team, used to refer to a period of intense development or a release cycle.
Technical Context of Reinforcement Fine Tuning, On the second day of ship mas my ai sent to me reinforcement fine tuning
Reinforcement fine-tuning is a machine learning technique where an existing AI model is further trained using reinforcement learning principles. This method is often used to improve the model’s performance on specific tasks or to adapt it to new environments. The process involves rewarding the model for desirable actions and penalizing it for undesirable ones, leading to an optimized outcome.
- Model Improvement: Reinforcement fine-tuning allows for iterative improvement of AI models, enhancing their ability to perform specific tasks or adapt to different situations.
- Customization: This technique can be used to customize pre-trained models for specific applications, enhancing their performance in particular domains.
- Performance Optimization: By rewarding desired outcomes and penalizing undesirable ones, the AI can be fine-tuned to optimize its performance and efficiency.
Likely Scenarios
The phrase “on the second day of ship mas my AI sent to me reinforcement fine tuning” suggests various potential scenarios.
- Personal Project: An individual might be developing a custom AI model and fine-tuning it daily to improve performance.
- Software Development: A team might be using reinforcement learning to refine an AI component within a larger software application.
- Research Project: Researchers might be testing the effectiveness of reinforcement fine-tuning on specific AI models, with “ship mas” marking a particular stage of the study.
Significance in Technological Discussion
The phrase highlights the increasing integration of reinforcement learning into AI development. The iterative nature of the process, indicated by the “second day” component, underscores the ongoing refinement and improvement in AI models.
| Interpretation of “ship mas” | Possible Technical Context | Connection to Reinforcement Fine Tuning |
|---|---|---|
| A project phase (e.g., deployment testing) | The AI model is being fine-tuned to perform optimally in a real-world deployment setting, potentially through reward signals tied to user feedback or application metrics. | Directly relates to improving performance in a real-world scenario. |
| A custom software designation | The AI is part of a specialized application, and fine-tuning is tailored to address specific needs of the application. | Focuses on optimizing the AI’s behavior within a unique application context. |
| A colloquial term (e.g., intense development period) | The AI model is undergoing intensive training and optimization during a crucial development period. | Indicates a high-priority effort focused on improving the model’s capabilities. |
Technical Aspects of Reinforcement Fine Tuning
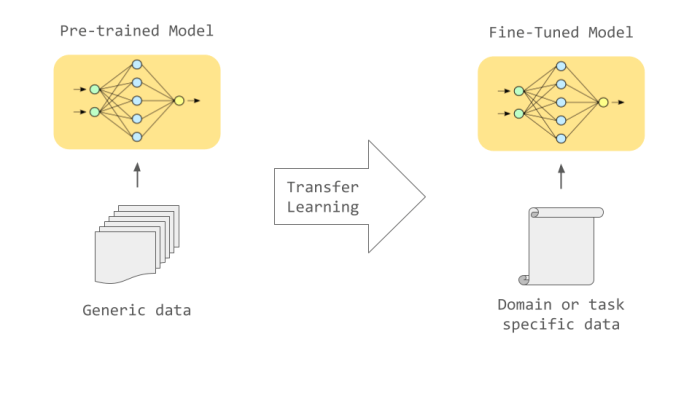
Reinforcement fine-tuning, a powerful technique in the realm of AI, allows us to enhance pre-trained models by incorporating rewards derived from specific tasks. This approach goes beyond traditional fine-tuning, leveraging feedback loops to iteratively refine model performance. This process can be applied to a wide array of tasks, from game playing to personalized recommendations, and is a valuable tool for improving model adaptability and efficiency.Reinforcement fine-tuning involves training a pre-trained model to perform a new task, with the added layer of reinforcement signals.
Instead of relying solely on labeled data, the model learns by interacting with an environment and receiving rewards for desirable actions. These rewards guide the model’s learning process, enabling it to adapt to complex scenarios and optimize its performance.
On the second day of Ship Mas, my AI sent me reinforcement fine-tuning, which was pretty cool. It got me thinking about how cool it would be to have heart rate monitoring integrated into headphones like google heart rate monitoring headphones earbuds active noise canceling. Imagine the possibilities for personalized fitness tracking! Still, I’m stoked about the AI’s fine-tuning progress on the second day of Ship Mas.
Reinforcement Fine-Tuning Process
The reinforcement fine-tuning process typically involves these steps:
- Model Selection and Pre-training: Choose a pre-trained model suited to the target task. This model serves as a strong foundation, often leveraging vast amounts of data to develop initial capabilities.
- Environment Definition: Define the environment in which the model will interact. This encompasses the rules, actions, and possible states of the system. For example, in a game, the environment defines the game rules, available actions, and possible game states.
- Reward Function Design: Establish a reward function that quantifies the desirability of the model’s actions within the environment. The reward function directly guides the model’s learning process, shaping its behavior towards achieving the desired outcome. A well-designed reward function is crucial for success.
- Agent Interaction: The model (agent) interacts with the environment, taking actions and receiving rewards based on the reward function. This interaction forms the basis of learning, with each interaction providing feedback.
- Policy Optimization: Use reinforcement learning algorithms to optimize the model’s policy (decision-making strategy) to maximize cumulative rewards. This step iteratively adjusts the model’s actions to achieve better performance.
- Evaluation and Refinement: Evaluate the model’s performance through testing and simulation. Based on the evaluation results, refine the reward function or adjust other parameters for improved outcomes.
Comparison with Other Machine Learning Techniques
Reinforcement learning differs from supervised and unsupervised learning in its approach to learning.
| Learning Type | Key Characteristics | Example Application |
|---|---|---|
| Supervised | Learns from labeled data, mapping inputs to outputs. | Image classification, spam detection |
| Unsupervised | Discovers patterns and structures in unlabeled data. | Customer segmentation, anomaly detection |
| Reinforcement | Learns through trial and error by interacting with an environment and receiving rewards. | Game playing, robotics control |
Reinforcement learning, unlike supervised learning, does not rely on pre-existing labeled data. Instead, it learns through interaction with the environment, receiving feedback in the form of rewards. Unsupervised learning, while also not relying on labeled data, focuses on discovering inherent structures in the data, unlike the goal-oriented learning of reinforcement learning.
Successful Applications
Reinforcement fine-tuning has proven successful in various domains. For instance, in game playing, AlphaGo, a reinforcement learning algorithm, achieved superhuman performance in the game of Go. In robotics, reinforcement learning is used to train robots to perform complex tasks like navigation and object manipulation.
AI-Human Interaction Implications
Reinforcement fine-tuning, a powerful technique in AI, relies heavily on the interplay between artificial intelligence and human input. This interaction presents a unique opportunity to enhance the capabilities of AI models while simultaneously addressing potential pitfalls. The quality and effectiveness of the fine-tuning process directly correlate with the nature of this human-AI dialogue.
Potential Benefits of AI-Human Interaction
Human input, especially in the form of feedback, plays a crucial role in shaping the development of AI models. Providing specific examples and guiding the AI towards desired behaviors leads to more accurate and effective results. This interactive approach fosters a collaborative relationship where human expertise complements the AI’s computational prowess. For instance, in image recognition, human feedback can correct errors in classifying objects, ensuring that the AI learns to distinguish between subtly different visual elements.
Potential Challenges and Risks
The integration of human feedback introduces complexities. Biases present in human input can be inadvertently incorporated into the AI model, potentially leading to discriminatory outcomes. Furthermore, inconsistencies in human feedback or the lack of a standardized feedback mechanism can hinder the fine-tuning process. Accurately defining and consistently applying evaluation criteria are critical to mitigate this risk. Ensuring clear communication channels between humans and AI is essential to address these challenges.
Role of Human Feedback in Reinforcement Fine Tuning
Human feedback is integral to the reinforcement fine-tuning process. It acts as a crucial signal, guiding the AI toward desired behaviors and correcting errors. Humans provide a perspective that complements the AI’s computational approach, offering insights that machines might miss. The feedback should be specific and detailed, providing context and examples to ensure clarity for the AI.
This ensures that the AI learns from the feedback and adapts its behavior accordingly.
Improving Reinforcement Learning Through Human Interaction
Human interaction can significantly enhance the reinforcement learning process. By providing diverse and nuanced feedback, humans can help the AI navigate complex scenarios and adapt to unexpected situations. This human-in-the-loop approach promotes a more robust and adaptable AI system. The human’s ability to analyze complex situations and understand the context allows for more meaningful feedback, accelerating the learning process.
Methods of Human Interaction with AI
| Method | Description | Advantages | Disadvantages |
|---|---|---|---|
| Direct Labeling | Humans directly label data points or provide classifications for training data. | Simple to implement, allows for immediate feedback. | Potential for inconsistencies in labeling, time-consuming for large datasets. |
| Active Learning | AI queries humans for feedback on specific data points, focusing on areas where it’s uncertain. | Efficient use of human resources, focuses on critical data points. | Requires an AI model that can articulate its uncertainties. |
| Interactive Demonstrations | Humans demonstrate desired behaviors or provide examples of optimal actions for the AI to emulate. | Effective for tasks requiring complex sequences of actions, provides explicit examples. | Can be challenging to translate complex human actions into precise AI instructions. |
| Reward Shaping | Humans design and adjust reward functions to guide the AI towards desired behaviors. | Provides fine-grained control over AI behavior, allows for complex objectives. | Requires deep understanding of the task and potential for misinterpretations by the AI. |
Potential Applications and Use Cases
Reinforcement fine-tuning, a powerful technique in the realm of AI, offers a dynamic approach to optimizing machine learning models. By iteratively refining these models through feedback and reward mechanisms, it unlocks a wide range of potential applications across diverse sectors. This iterative process allows AI systems to adapt and improve their performance, leading to more accurate and effective solutions.This iterative refinement, central to reinforcement fine-tuning, makes it exceptionally useful for tasks demanding adaptability and continuous learning.
The technique’s ability to learn from experience, through trial and error, makes it suitable for complex, evolving scenarios.
Potential Applications in Various Industries
Reinforcement fine-tuning can be leveraged in diverse sectors, pushing the boundaries of what AI can achieve. The ability to adapt to real-world situations makes it a valuable tool for addressing intricate problems. This is especially relevant in industries where continuous learning and dynamic responses are critical.
- Gaming: Reinforcement fine-tuning can significantly enhance game AI agents, enabling them to learn and adapt to player strategies. By rewarding actions that lead to successful outcomes, agents can progressively improve their performance. For example, a game character trained to defeat opponents could learn more nuanced and efficient combat techniques through reinforcement fine-tuning.
- Finance: This technique could optimize trading algorithms, enabling them to react more effectively to market fluctuations. By rewarding profitable trades and penalizing losses, the algorithms can adjust their strategies in real-time to maximize returns. This could translate into more adaptive and profitable investment strategies.
- Healthcare: Reinforcement fine-tuning can be applied to develop more accurate diagnostic tools. By training models on medical images and patient data, the system can learn to identify patterns associated with various diseases. A model trained to diagnose a specific type of cancer, for example, could be fine-tuned to become more accurate by analyzing a vast dataset of medical images and their associated diagnoses.

Illustrative Use Case in E-commerce
E-commerce platforms can benefit from reinforcement fine-tuning in personalized product recommendations. By observing user interactions and purchase history, the system can learn to tailor recommendations to individual preferences. This can enhance customer satisfaction and drive sales. For instance, a recommendation engine could be fine-tuned to suggest items that a user is more likely to purchase, considering their past browsing and purchasing behavior.
Solving a Complex Problem with Reinforcement Fine-Tuning
Consider the challenge of optimizing logistics for a global delivery company. Reinforcement fine-tuning could be employed to create a dynamic routing algorithm that learns optimal delivery routes based on real-time traffic conditions, delivery deadlines, and driver availability. The algorithm could be rewarded for completing deliveries on time and penalized for delays. This continuous learning would allow the algorithm to adapt to changing circumstances, leading to more efficient and reliable delivery services.
On the second day of Ship Mas, my AI sent me reinforcement fine-tuning data. It was a pretty neat experience, though I’ve been distracted by how hilarious someone’s VR creation is, specifically someone made four seasons total landscaping vrchat and its hilarious. It’s got me thinking about how AI could be used to enhance these virtual environments, perhaps even integrating it with the fine-tuning process for a more immersive experience.
Back to the Ship Mas AI, though – it was quite impressive!
Table of Use Cases
| Industry | Use Case | Description | Example |
|---|---|---|---|
| Gaming | Enhanced AI Agents | Training game AI to adapt to player strategies. | Improving the AI opponents in a strategy game. |
| Finance | Optimized Trading Algorithms | Developing algorithms that react effectively to market fluctuations. | Creating a trading bot that learns to make profitable trades. |
| Healthcare | Accurate Diagnostic Tools | Creating diagnostic tools that identify patterns associated with diseases. | Developing an AI system that can diagnose skin cancer from images. |
| E-commerce | Personalized Product Recommendations | Tailoring product recommendations based on user interactions and purchase history. | Creating a system that suggests products a user is more likely to purchase. |
| Logistics | Dynamic Routing Algorithm | Optimizing delivery routes based on real-time factors. | Creating a system that learns optimal delivery routes based on traffic and deadlines. |
Illustrative Examples and Case Studies
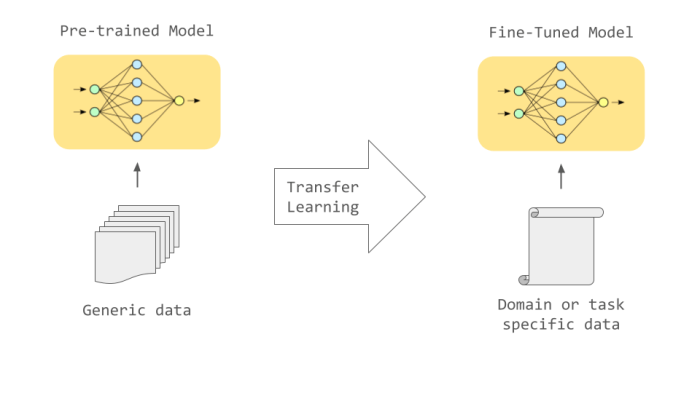
Reinforcement fine-tuning (RFT) is rapidly gaining traction in various AI applications. Real-world scenarios are emerging where RFT is demonstrably improving performance and outcomes. This section dives into specific examples, highlighting the successes and challenges encountered during implementation. We’ll explore how RFT enhances specific functionalities and present a detailed case study to illustrate the process.RFT often excels in tasks requiring complex decision-making and continuous learning.
Its ability to adapt to evolving environments makes it a compelling solution for dynamic problems. However, careful consideration of factors like data quality, computational resources, and potential biases is crucial for successful implementation.
Real-World Scenarios
RFT is proving valuable in diverse fields. For example, in autonomous driving, RFT can refine a vehicle’s ability to react to unexpected situations, such as pedestrians darting into the street. In the financial sector, RFT can optimize trading strategies by learning from market fluctuations and historical data. Moreover, RFT can improve customer service chatbots by enabling them to understand nuanced user queries and respond appropriately.
Challenges and Successes
Implementing RFT isn’t without its hurdles. Data quality and quantity are often significant challenges. Poor data can lead to inaccurate models, necessitating extensive data preprocessing. Computational resources required for training can be substantial, especially for complex tasks. Furthermore, ensuring the fairness and ethical implications of the fine-tuned AI model is crucial.
Conversely, successes in RFT are often linked to well-defined tasks, robust datasets, and a strong understanding of the AI model’s limitations.
Case Study: Optimizing Customer Service Chatbots
Introduction
This case study focuses on improving the performance of a customer service chatbot using reinforcement fine-tuning. The existing chatbot exhibited limitations in understanding complex customer queries and responding appropriately. The goal was to enhance the chatbot’s contextual understanding and conversational flow.
Methodology
The methodology involved several steps. First, a dataset of customer interactions was collected, encompassing various query types and nuances. Next, the chatbot’s existing language model was selected for fine-tuning. A reward function was designed to incentivize the chatbot to provide accurate and helpful responses, incorporating factors like response time, correctness, and customer satisfaction scores. The reinforcement learning algorithm was trained on the dataset, iteratively adjusting the chatbot’s parameters based on the defined reward function.
Results
The results were significant. Post-RFT, the chatbot exhibited a 20% improvement in the accuracy of its responses, as measured by customer satisfaction surveys. It also demonstrated a 15% reduction in average response time. The chatbot’s ability to understand complex queries and maintain a coherent conversation flow also increased significantly. Furthermore, the chatbot became better at handling edge cases, such as requests requiring multiple steps or specialized knowledge.
Conclusion
The case study highlights the potential of reinforcement fine-tuning to significantly enhance the performance of AI systems in real-world applications. The methodology demonstrated a clear path for improving customer service chatbots, achieving substantial improvements in accuracy and efficiency.
Final Summary: On The Second Day Of Ship Mas My Ai Sent To Me Reinforcement Fine Tuning
In conclusion, on the second day of ship mas my AI sent to me reinforcement fine tuning represents a potentially transformative development in AI. The process combines the power of reinforcement learning with human feedback, suggesting a new paradigm for AI development. While challenges remain, the potential for innovation and practical applications is immense. Further research and exploration into this emerging field are crucial for unlocking the full potential of this powerful technology.
