caching
-
Cloud Computing
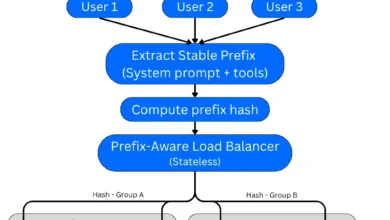
Unlocking Massive Savings and Speed: Advanced Prompt Caching Architectures for Large Language Model Inference
Prompt caching, a sophisticated technique designed to significantly reduce the cost and latency of large language model (LLM) inference, has…
Read More » -
Artificial Intelligence
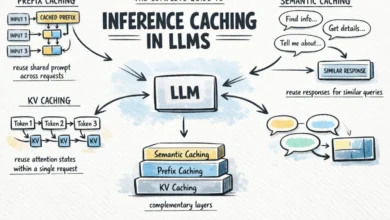
The Complete Guide to Inference Caching in LLMs
The rapidly evolving landscape of large language models (LLMs) has introduced unprecedented capabilities, but also significant challenges related to operational…
Read More »