architectures
-
Cloud Computing
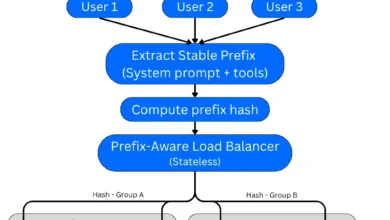
Unlocking Massive Savings and Speed: Advanced Prompt Caching Architectures for Large Language Model Inference
Prompt caching, a sophisticated technique designed to significantly reduce the cost and latency of large language model (LLM) inference, has…
Read More »