GitHub Leverages eBPF to Fortify Deployment Resilience Against Circular Dependencies

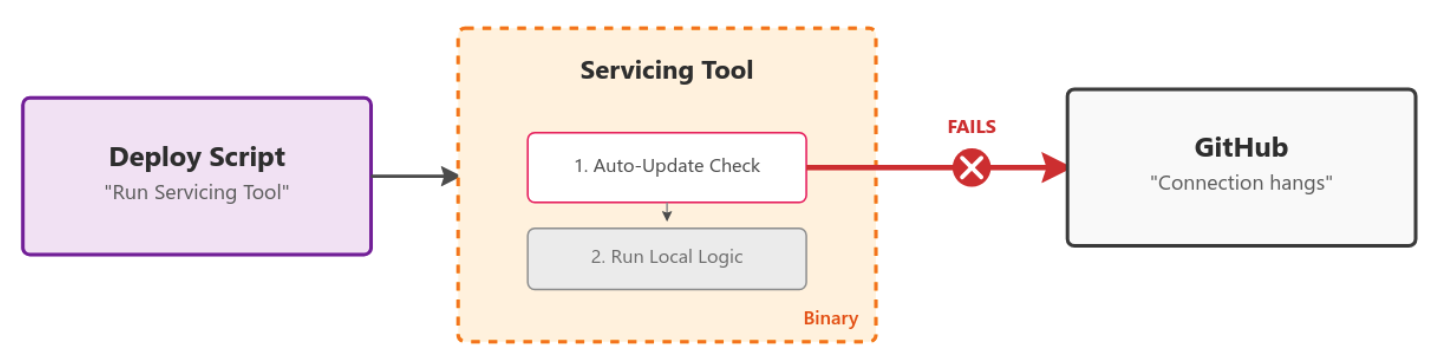
GitHub, a cornerstone of the modern software development ecosystem, has successfully implemented an innovative eBPF-based system to detect and prevent circular dependencies within its deployment tooling, significantly enhancing platform stability and accelerating incident recovery. The challenge of maintaining the world’s largest collection of open-source code, while simultaneously hosting its own source code on github.com, presents a unique set of operational complexities. This self-hosting model, where GitHub is its own "biggest customer," allows for rigorous internal testing before features reach external users. However, it also introduces a fundamental circular dependency: deploying updates or fixes to GitHub often requires access to GitHub itself. Should github.com experience an outage, the ability to access its source code and deployment tools could be severely hampered, creating a critical roadblock to recovery.
Initially, this primary circular dependency was mitigated through established fallback mechanisms, including maintaining offline mirrors of critical code and pre-built assets for rapid rollbacks. This ensures that even if the main platform is inaccessible, essential repair operations can proceed. Yet, as GitHub’s infrastructure grew in complexity, a more subtle and pervasive threat emerged: secondary circular dependencies introduced by deployment scripts and internal services. These dependencies, often unintentional, could call upon other GitHub services or external resources that might themselves be affected by an incident, leading to a cascading failure during critical recovery periods. Identifying and addressing these latent issues before they manifest during an outage became a paramount operational goal.
The Unseen Threat: Deeper Circular Dependencies
The problem extends far beyond the explicit "GitHub needs GitHub" scenario. Consider a hypothetical, yet all too real, incident: a MySQL outage impacting the ability to serve release data from repositories. To resolve this, a configuration change might need to be applied to the affected stateful MySQL nodes via a specialized deploy script. This seemingly straightforward process is fraught with potential circular dependencies.
One common pitfall involves deployment scripts that attempt to pull the latest version of an open-source tool or binary directly from github.com during execution. If the platform is already experiencing an outage, this download will fail, rendering the deployment script inoperable and preventing the necessary fix from being applied. Another layer of complexity arises when a deployment script calls an internal API, which in turn relies on GitHub to fetch a new binary or configuration. This creates a chain of dependencies where a failure at the initial GitHub layer propagates through the internal service, ultimately blocking the deployment script. Such scenarios highlight the insidious nature of these dependencies; they are often not immediately apparent and can remain dormant until an incident exposes them, delaying mean time to recovery (MTTR).

Historically, the responsibility for identifying these circular dependencies fell to individual engineering teams managing stateful hosts. This largely manual review process was inherently reactive, with many dependencies only surfacing during an actual incident. The traditional approach of simply blocking access to github.com from deployment machines for validation purposes was also impractical. These machines are integral to serving customer traffic and cannot have their network access entirely cut off without impacting production, even during rolling deploys or restarts. A more sophisticated, dynamic, and granular solution was required.
eBPF: A Kernel-Level Revolution for Network Control
In the quest for a proactive and automated solution, GitHub’s engineering teams turned their attention to eBPF (extended Berkeley Packet Filter). eBPF is a revolutionary technology that allows developers to run custom programs safely within the Linux kernel without changing kernel source code or loading kernel modules. This capability provides unprecedented visibility and control over system primitives, including networking, process management, and file systems. For GitHub’s challenge, eBPF’s ability to hook into core system functions at a low level offered a promising avenue for selectively monitoring and blocking network calls made by deployment scripts.
Specifically, the BPF_PROG_TYPE_CGROUP_SKB program type caught the engineers’ attention. This eBPF program type enables filtering network egress (outbound traffic) from a particular cGroup. A cGroup (control group) is a Linux kernel feature that organizes processes hierarchically and allocates system resources (CPU, memory, network I/O, etc.) among them. Crucially, cGroups provide isolation, meaning that a process can be placed within a cGroup, and its resource usage and network interactions can be controlled independently of other processes on the same host. This offered the ideal primitive for isolating deployment scripts and applying granular network policies to them without affecting other production workloads running on the same machine.
The hypothesis was compelling: Could a cGroup be created, a deployment script placed within it, and its outbound network access then strictly controlled using an eBPF program? The potential to achieve per-process conditional network filtering at the kernel level, with minimal overhead and maximum flexibility, made eBPF an attractive candidate.
Engineering the Solution: From Concept to Code

The journey began with building a proof of concept (PoC) using Go, leveraging the cilium/ebpf library. This library simplifies the development lifecycle of eBPF programs, allowing Go developers to read, modify, load, and attach eBPF programs to various kernel hooks. It abstracts away much of the complexity of interacting directly with the kernel, enabling faster iteration and development.
The initial PoC demonstrated the basic principle of attaching an eBPF program to a cGroup’s network egress. The Go code snippet provided in the original article illustrates how the count_egress_packets eBPF program, written in C, is loaded and linked to the /sys/fs/cgroup/system.slice path, which represents a cGroup. This program simply counts outbound packets, showcasing the ability to intercept and process network traffic.
//go:generate go tool bpf2go -tags linux bpf cgroup_skb.c -- -I../headers
func main()
// Load pre-compiled programs and maps into the kernel.
objs := bpfObjects
if err := loadBpfObjects(&objs, nil); err != nil
log.Fatalf("loading objects: %v", err)
defer objs.Close()
// Link the count_egress_packets program to the cgroup.
l, err := link.AttachCgroup(link.CgroupOptions
Path: "/sys/fs/cgroup/system.slice",
Attach: ebpf.AttachCGroupInetEgress,
Program: objs.CountEgressPackets,
)
if err != nil
log.Fatal(err)
defer l.Close()
log.Println("Counting packets...")
// Read loop reporting the total amount of times the kernel
// function was entered, once per second.
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for range ticker.C
var value uint64
if err := objs.PktCount.Lookup(uint32(0), &value); err != nil
log.Fatalf("reading map: %v", err)
log.Printf("number of packets: %dn", value)
And the corresponding eBPF C code:
//go:build ignore
#include "common.h"
char __license[] SEC("license") = "Dual MIT/GPL";
struct
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, u32);
__type(value, u64);
__uint(max_entries, 1);
pkt_count SEC(".maps");
SEC("cgroup_skb/egress")
int count_egress_packets(struct __sk_buff *skb)
u32 key = 0;
u64 init_val = 1;
u64 *count = bpf_map_lookup_elem(&pkt_count, &key);
if (!count)
bpf_map_update_elem(&pkt_count, &key, &init_val, BPF_ANY);
return 1;
__sync_fetch_and_add(count, 1);
return 1;
This demonstrated the foundational capability, but a significant hurdle remained: CGROUP_SKB operates on IP addresses. For an infrastructure as vast and dynamic as GitHub’s, maintaining an up-to-date blocklist of IP addresses for github.com and other internal services would be an intractable management nightmare. IP addresses change, services scale, and new endpoints are introduced regularly. A more abstract, domain-name-based filtering mechanism was essential.
Dynamic DNS Filtering and Process Attribution
The solution to the IP address problem came from another powerful eBPF program type: BPF_PROG_TYPE_CGROUP_SOCK_ADDR. This type allows eBPF programs to hook into syscalls related to socket creation and connection attempts, crucially enabling the modification of the destination IP address. By attaching such a program, GitHub engineers could intercept DNS queries (typically on Port 53) originating from within the isolated cGroup and redirect them to a userspace DNS proxy running on localhost.
The code snippet illustrates this redirection:
cgroupLink, err := link.AttachCgroup(link.CgroupOptions
Path: cgroup.Name(),
Attach: ebpf.AttachCGroupInet4Connect,
Program: obj.Connect4,
)
if err != nil
return nil, fmt.Errorf("attaching eBPF program Connect4 to cgroup: %w", err)
And the eBPF C code for the connect4 hook:
/* This is the hexadecimal representation of 127.0.0.1 address */
const __u32 ADDRESS_LOCALHOST_NETBYTEORDER = bpf_htonl(0x7f000001);
SEC("cgroup/connect4")
int connect4(struct bpf_sock_addr *ctx)
__be32 original_ip = ctx->user_ip4;
__u16 original_port = bpf_ntohs(ctx->user_port);
if (ctx->user_port == bpf_htons(53))
/* For DNS Query (*:53) rewire service to backend
* 127.0.0.1:const_dns_proxy_port */
ctx->user_ip4 = const_mitm_proxy_address;
ctx->user_port = bpf_htons(const_dns_proxy_port);
return 1;
With this mechanism in place, all DNS queries initiated by processes within the designated cGroup are routed through GitHub’s custom userspace DNS proxy. This proxy then evaluates each requested domain against a dynamically managed blocklist. If a domain, such as github.com, is on the blocklist, the proxy can either return a non-resolvable IP or, in conjunction with eBPF Maps, instruct the CGROUP_SKB program to drop any subsequent network packets targeting that domain’s resolved IP. eBPF Maps are key-value data structures that allow eBPF programs to share data with other eBPF programs or with userspace applications, enabling dynamic configuration and communication.
A crucial enhancement to this system was the ability to correlate blocked DNS requests back to the specific process and command that initiated them. This is vital for debugging and empowering teams to quickly identify and fix problematic dependencies. Inside the BPF_PROG_TYPE_CGROUP_SKB program, engineers can extract the DNS transaction ID from the skb_buff (socket buffer) and capture the Process ID (PID) using bpf_get_current_pid_tgid(). This information is then stored in an eBPF Map, mapping DNS Transaction ID -> Process ID.
__u32 pid = bpf_get_current_pid_tgid() >> 32;
__u16 skb_read_offset = sizeof(struct iphdr) + sizeof(struct udphdr);
__u16 dns_transaction_id =
get_transaction_id_from_dns_header(skb, skb_read_offset);
if (pid && dns_transaction_id != 0)
bpf_map_update_elem(&dns_transaction_id_to_pid, &dns_transaction_id,
pid, BPF_ANY);
When the userspace DNS proxy intercepts a blocked DNS query, it can use the transaction ID to look up the corresponding PID in the eBPF Map. Further, by reading /proc/PID/cmdline, the full command line that triggered the request can be extracted. This rich contextual information is then used to generate informative log lines, such as:
> WARN DNS BLOCKED reason=FromDNSRequest blocked=true blockedAt=dns domain=github.com. pid=266767 cmd="curl github.com " firewallMethod=blocklist

This level of detail transforms a cryptic network error into an actionable insight, allowing developers to pinpoint and rectify circular dependencies efficiently.
The Rollout and Impact: A More Resilient GitHub
The new circular dependency detection system, built upon eBPF, has undergone a rigorous six-month rollout across GitHub’s extensive infrastructure. It is now fully live, actively safeguarding deployments. This advanced tooling provides an automated safety net: if a team inadvertently introduces a problematic dependency into a deployment script, or if an existing binary tool acquires a new, undesirable dependency, the system immediately flags the issue.
The immediate and tangible benefits are profound:
- Proactive Detection: Dependencies are identified before an incident, preventing them from causing further disruption during critical recovery phases.
- Enhanced Stability: By eliminating these vulnerabilities, GitHub’s platform becomes inherently more stable and resilient to outages.
- Faster Incident Recovery: The removal of circular dependencies directly contributes to a reduced mean time to recovery (MTTR) when incidents do occur, as deployment scripts can reliably execute without external interference.
- Reduced Operational Burden: Teams no longer rely solely on error-prone manual reviews, allowing them to focus on feature development and core services.
- Granular Control: The eBPF-based solution offers surgical precision in network filtering, impacting only the isolated deployment process within its cGroup, without affecting co-located production workloads.
While the current system marks a significant achievement, GitHub’s engineers recognize that the landscape of dependencies is ever-evolving. There are always new ways for circular dependencies to emerge, and the tooling will continue to be improved and refined as new patterns are discovered.
Broader Implications for Cloud Infrastructure

GitHub’s successful implementation of eBPF for circular dependency management serves as a powerful case study for the broader cloud and infrastructure community. It demonstrates the immense potential of eBPF to solve complex operational challenges at scale, particularly in environments where traditional network filtering or application-level solutions are insufficient or too cumbersome.
The principles applied by GitHub – leveraging eBPF for per-process network isolation, dynamic DNS interception, and detailed process attribution – can be adapted by other organizations facing similar challenges in their deployment pipelines or service mesh architectures. As microservices and distributed systems become more prevalent, the risk of hidden circular dependencies grows, making robust detection and prevention mechanisms indispensable.
Furthermore, this initiative highlights the maturity and versatility of the eBPF ecosystem. Tools like cilium/ebpf make kernel-level programming more accessible to a wider developer audience, fostering innovation. For those not yet ready to write their own eBPF programs, the growing array of open-source tools powered by eBPF, such as bpftrace for deep tracing and ptcpdump for enhanced TCP dumps with container-level metadata, offers immediate benefits for observability and troubleshooting.
Looking Ahead: Continuous Improvement and Community Engagement
The journey for GitHub’s deployment resilience is ongoing. The engineering teams are committed to continuously improving the eBPF-based tooling, adapting it to new architectural patterns and potential dependency vectors. This iterative approach ensures that GitHub remains at the forefront of operational excellence.
Beyond internal benefits, GitHub actively encourages the wider developer community to explore the capabilities of eBPF. The rich documentation on docs.ebpf.io and the comprehensive examples in cilium/ebpf provide excellent starting points for anyone looking to dive into this transformative technology. By sharing their experiences and solutions, GitHub not only fortifies its own platform but also contributes valuable insights and practical applications that can benefit the entire industry, fostering a more stable and resilient internet for all.






{kind=link}