Changes to the status page will provide more specific data, so you’ll have better insight into the overall health of the platform.
GitHub, a cornerstone of the global software development landscape, has unveiled a significant overhaul of its service status communication, rolling out three key enhancements designed to provide developers with unprecedented clarity and insight into the platform’s operational health. This strategic move comes on the heels of earlier availability challenges faced by the company, underscoring a renewed commitment to transparency, accuracy, and timeliness in incident reporting. For millions of developers worldwide who rely on GitHub for their mission-critical work, these updates promise a more precise understanding of service disruptions, enabling better-informed decision-making and operational planning.
The digital infrastructure underpinning modern software development is complex, and GitHub stands as a central pillar, hosting vast repositories, facilitating collaborative coding, and powering continuous integration/continuous deployment (CI/CD) pipelines. Any disruption to its services can ripple across countless projects, affecting development cycles, deployment schedules, and ultimately, the delivery of software solutions. Recognizing this profound responsibility, GitHub had previously acknowledged "recent availability issues" and committed to substantial investments in reliability. Alongside these technical improvements, the company has now prioritized refining its communication protocols during and after incidents, aiming to elevate the specificity of data and enhance overall platform health visibility.
A New Era of Transparency: The Core Principles
Guided by the overarching principles of transparency, accuracy, and timeliness, GitHub’s latest initiative introduces a multi-faceted approach to service health communication. These changes are not merely cosmetic; they represent a fundamental shift in how GitHub classifies, reports, and contextualizes service interruptions. The ultimate goal is to empower users with the granular details necessary to navigate potential disruptions with confidence, mitigating their impact on development workflows.
The updates address long-standing feedback from the developer community regarding the need for more nuanced incident reporting. In an increasingly interconnected and always-on world, a simple "outage" notification often fails to capture the full spectrum of service degradation, leading to confusion and frustration. GitHub’s response is a comprehensive framework designed to reflect the true state of its intricate ecosystem more accurately.
Enhancing Accuracy: A Three-Tiered Incident Severity System
One of the most impactful changes is the introduction of a new incident severity level: Degraded Performance. This new classification slots into GitHub’s existing framework, creating a robust three-tier system that offers a far more accurate reflection of the varied issues that can affect its services. Previously, even minor service disruptions might have been broadly categorized as a "Partial Outage," which often overstated the actual impact and led users to believe a service was entirely unavailable when it was still largely functional, albeit with some limitations.
The revised incident severity levels are defined as follows:
- Degraded Performance: This new state signifies that a service is operational but impaired. Users might encounter elevated latency, reduced functionality, or intermittent errors affecting a small percentage of requests. Crucially, the service remains functional, distinguishing it from more severe disruptions. For instance, a temporary slowdown in Git push operations for a specific region, or sporadic failures in webhook deliveries that eventually retry successfully, would now fall under this category. This level provides critical differentiation, allowing developers to understand that while there might be minor issues, core functionality largely persists.
- Partial Outage: This category remains for situations where a significant portion of a service is unavailable or severely impacted for a meaningful number of users. This implies a more substantial disruption than degraded performance, affecting a noticeable segment of the user base or a core feature. An example might be a specific GitHub Actions runner environment being offline, or a subset of repository access experiencing failures for a sustained period.
- Major Outage: This represents the most severe level, indicating that the service is broadly unavailable, affecting most or all users. This signifies a widespread and critical failure, such as the entire GitHub.com platform being inaccessible or core functionalities like Git operations or pull request merging being completely down for the majority of users.
This tiered system moves beyond a binary "up or down" assessment, providing a more granular and realistic view of service health. By distinguishing between slight impairment and significant unavailability, GitHub empowers its users to make more informed decisions about whether to continue working, pause operations, or investigate alternative solutions. This level of detail is particularly valuable for organizations with strict internal SLAs or those managing complex CI/CD pipelines where even minor performance degradation can have cumulative effects.
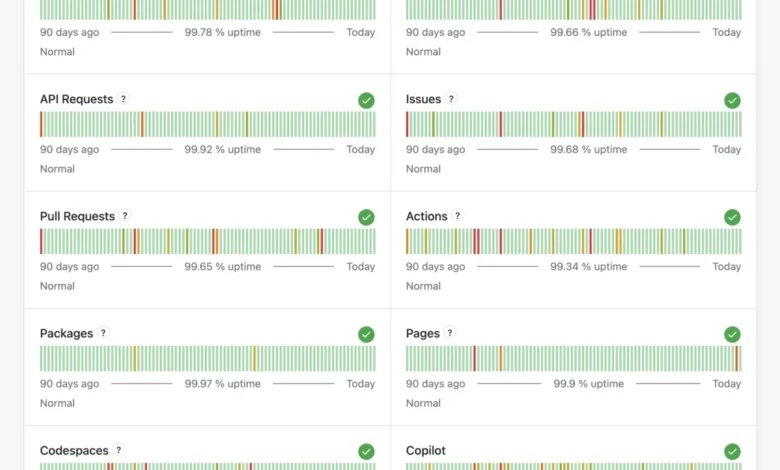
Per-Service Uptime: A Data-Driven Reliability Scorecard
Further bolstering transparency, GitHub is now publishing per-service uptime percentages over the last 90 days directly on its status page. This innovative feature provides a quick, at-a-glance understanding of each individual service’s recent reliability track record. This move is particularly significant for developers who often rely on specific GitHub components (e.g., GitHub Actions, GitHub Packages, GitHub Pages) and need to assess their individual stability.
These uptime percentages are calculated using an industry-standard methodology that takes into account the number of incidents, their severity, and their duration for each service. The weighting system applied to different severity levels is crucial for understanding these calculations:
- Major Outage: 100% downtime weight. The full duration of a major outage counts as downtime. This reflects the complete unavailability and critical impact on users.
- Partial Outage: 30% downtime weight. This acknowledges that while significant, a partial outage does not equate to total service loss. For example, a one-hour partial outage would contribute 18 minutes of effective downtime (30% of 60 minutes) to the uptime calculation. This pragmatic approach recognizes that some functionality may still be accessible or that only a subset of users is affected.
- Degraded Performance: 0% downtime weight. Incidents classified as "Degraded Performance" do not count as downtime in the uptime percentage calculation. This is because the service remains functional, even if impaired, emphasizing that core operations are still possible.
This detailed breakdown provides users with a transparent methodology for how uptime is measured, fostering greater trust in the reported figures. For developers building mission-critical applications or maintaining robust CI/CD pipelines, these per-service uptime metrics offer invaluable data points for risk assessment, vendor evaluation, and contingency planning. It allows them to quantify the reliability of the specific GitHub services they depend on, beyond a general platform-wide status.
Insights on Copilot AI Model Provider Service Disruptions: Specializing AI Reporting
The rapid integration of artificial intelligence into developer tools, epitomized by GitHub Copilot, introduces new complexities in service status reporting. GitHub has addressed this by adding a new component specifically representing Copilot AI Model Providers. This change is a direct response to the unique architecture of AI-powered services, which often rely on multiple underlying models from various providers.
Previously, if a single AI model provider experienced an outage, GitHub would declare an incident against the broader "Copilot service." This approach often misrepresented the actual user experience, as many Copilot features – such as GitHub Copilot Chat and the GitHub Copilot cloud agent (formerly coding agent) – are designed to support multiple models. In scenarios where one model was unavailable, users could often choose an alternative model or rely on Copilot’s auto-model selection feature to seamlessly pick the best available option. The previous reporting method, therefore, created an impression of a wider outage than was truly occurring.
Going forward, incidents related to the availability of specific AI models will be reported under the new "Copilot AI Model Providers" component. This granular reporting ensures that users understand precisely which models are affected, allowing them to leverage alternative models or the auto-selection capability more effectively. The broader "Copilot" component will now be reserved for issues affecting the overarching Copilot service itself, such as authentication problems or core infrastructure failures. GitHub has committed to continuing to share detailed public incident updates, including information on which specific models are impacted, providing developers with the full context needed to adjust their Copilot usage. This specialization in AI service reporting reflects the growing sophistication of developer tools and the necessity for equally sophisticated communication strategies.
The Broader Impact and Implications for the Developer Ecosystem
These comprehensive updates to GitHub’s status page represent more than just technical adjustments; they signify a deepening commitment to fostering trust and enabling developer productivity. For the millions of developers, teams, and enterprises that rely on GitHub as their foundational development platform, clearer communication during incidents translates directly into tangible benefits.
Firstly, enhanced transparency empowers developers to make more confident and timely decisions. When a service experiences "Degraded Performance" rather than a "Partial Outage," teams can assess the actual impact on their specific workflows and decide whether to proceed with minor adjustments or pause operations. This precision reduces unnecessary panic and allows for more efficient resource allocation.
Secondly, the per-service uptime percentages provide valuable data for risk management and compliance. Organizations can now quantitatively track the reliability of critical GitHub components, which can feed into their internal service level objectives (SLOs) and help them assess vendor performance. This is particularly crucial for heavily regulated industries or enterprises with strict uptime requirements.
Thirdly, the specialized reporting for Copilot AI Model Providers acknowledges the evolving landscape of developer tools. As AI integration becomes ubiquitous, understanding the nuances of AI service availability will be paramount. GitHub’s proactive approach sets a precedent for how complex, multi-component AI services should communicate their health, enabling developers to maximize the utility of these advanced tools even during partial disruptions.
These changes also reflect a broader industry trend where major cloud providers and SaaS platforms are increasingly expected to offer detailed, real-time insights into their operational status. Companies like AWS, Microsoft Azure, and Google Cloud Platform have long provided sophisticated status dashboards, and GitHub’s latest improvements align it firmly with these industry leaders in transparency. This competitive landscape drives innovation in incident management and communication, ultimately benefiting the end-users.
A Continued Commitment to Reliability and Trust
Jakub Oleksy, the author of the original GitHub blog post, underscored that "clear communication and transparency matter most when things go wrong." This sentiment resonates deeply within the developer community, where trust in critical infrastructure providers is paramount. The introduction of the Degraded Performance state, per-service uptime percentages, and the dedicated Copilot AI Model Providers component are meticulously designed to furnish users with the context and details essential for making confident decisions about their operations.
GitHub’s leadership has consistently emphasized its recognition of the platform’s role as critical infrastructure for countless teams globally. The company’s ongoing commitment extends beyond merely addressing technical issues; it encompasses ensuring the platform is available precisely when and where it is needed, and, equally important, communicating effectively and transparently when it is not. This holistic approach to reliability and user experience is crucial for maintaining GitHub’s position at the heart of the world’s software development.
The journey towards perfect uptime and instantaneous, flawless communication is continuous. However, these recent enhancements mark a significant leap forward in GitHub’s efforts to provide its vast user base with the visibility and control they need. By embracing a more granular, data-driven, and transparent communication strategy, GitHub reinforces its dedication to supporting the global developer community and ensuring the smooth functioning of the software development lifecycle.





{kind=link}